2
4
7
新手上路
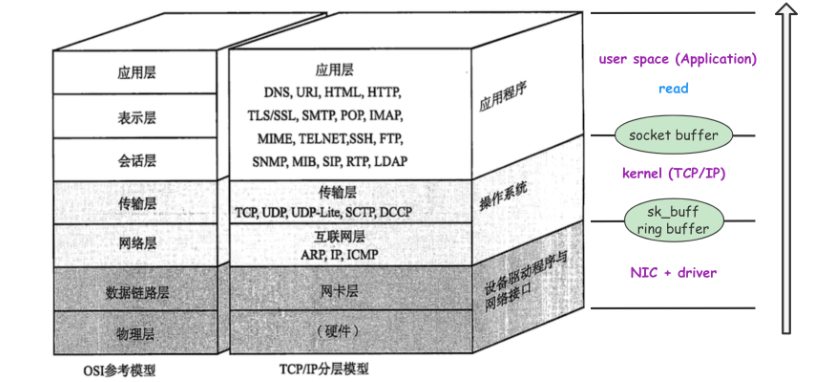
图片来源:《图解 TCP_IP》
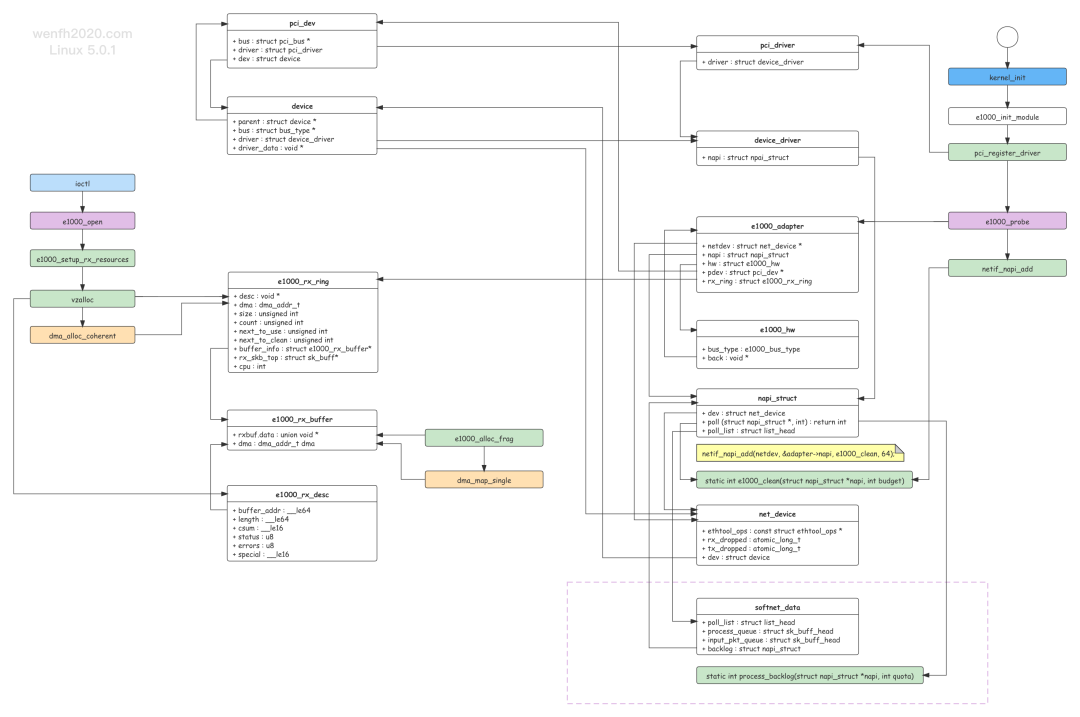
PCI 是 Peripheral Component Interconnect (外设部件互连标准) 的缩写,它是目前个人电脑中使用最为广泛的接口,几乎所有的主板产品上都带有这种插槽。
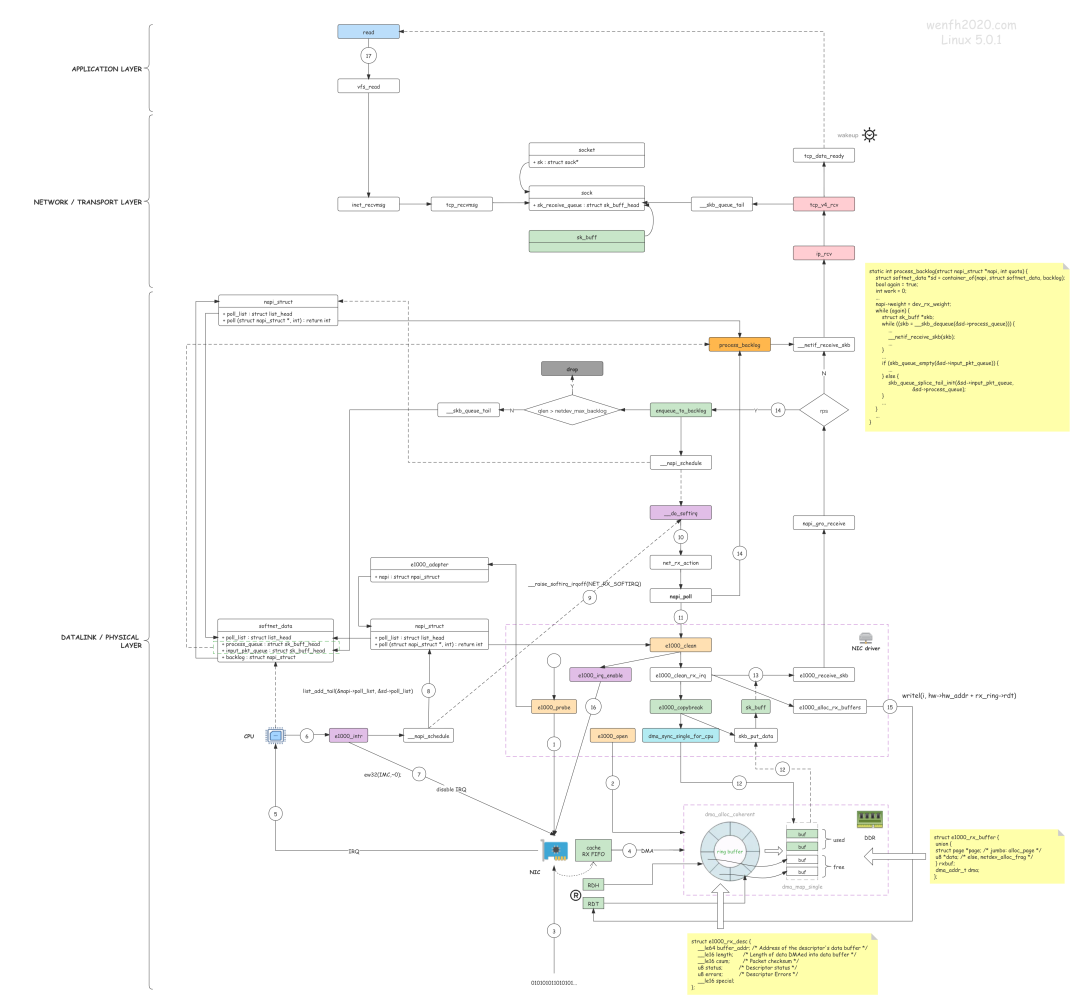
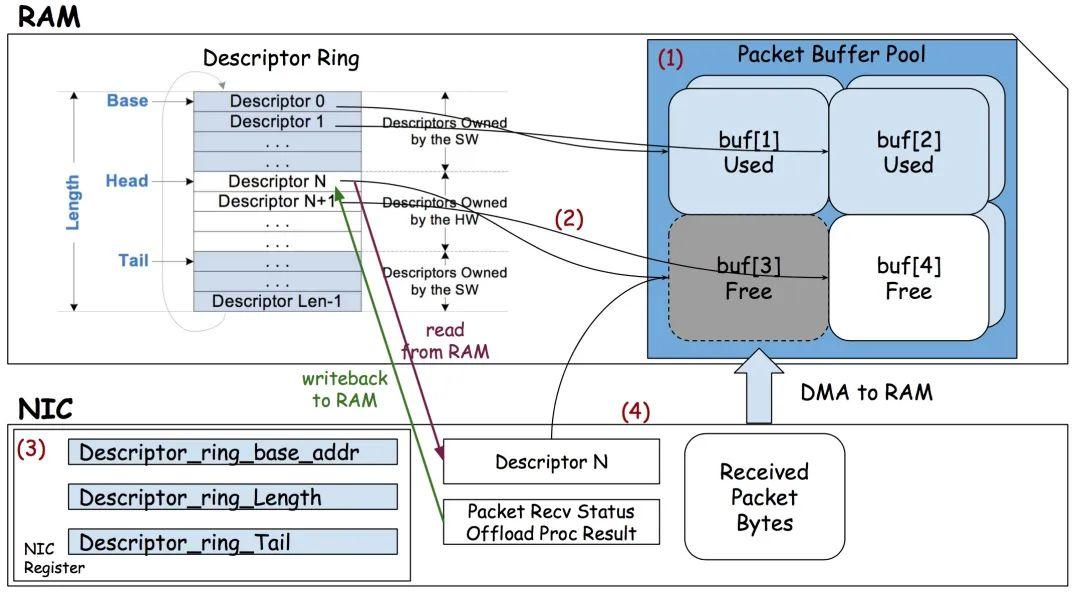
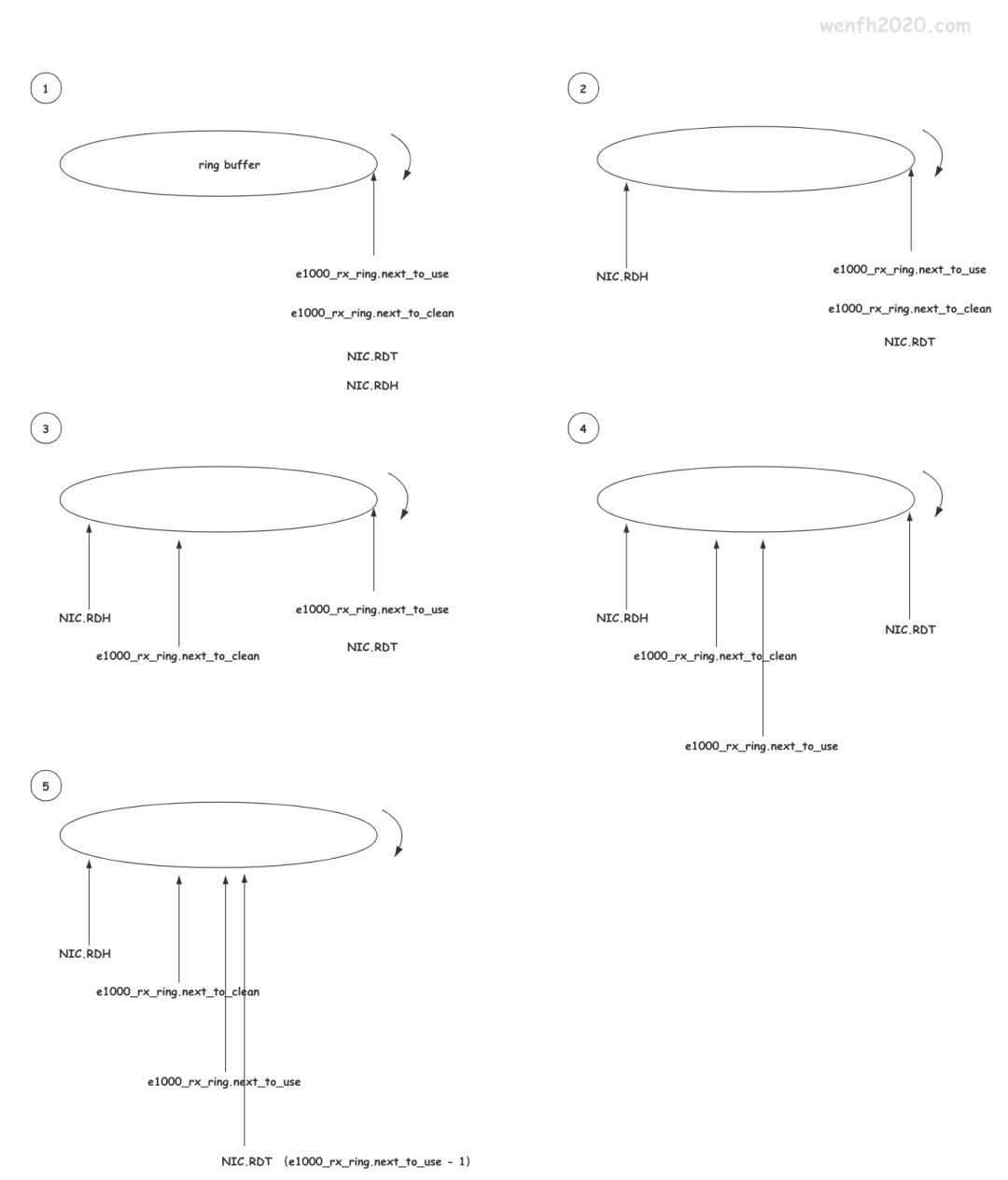
举个 :餐厅人少时,客户点菜,服务员可以一对一提供服务,客户点一个菜,服务员记录一下;但是人多了,服务员就忙不过来了,这时服务员可以为每张桌子提供一张菜单,客户慢慢看,选好菜了,就通知服务员处理,这样效率就高很多了。
使用道具 举报
1
3
5
本版积分规则 发表回复 回帖后跳转到最后一页
云顶设计嘉兴有限公司模板设计.
免责声明:本站上数据均为演示站数据,如购买模板可以上DISCUZ应用中心购买,欢迎惠顾.
云顶官方站点:云顶设计 模板原创设计:云顶模板 Powered by Discuz! X3.4© 2001-2017 Comsenz Inc.



 发表于 2022-9-21 15:29:05
发表于 2022-9-21 15:29:05