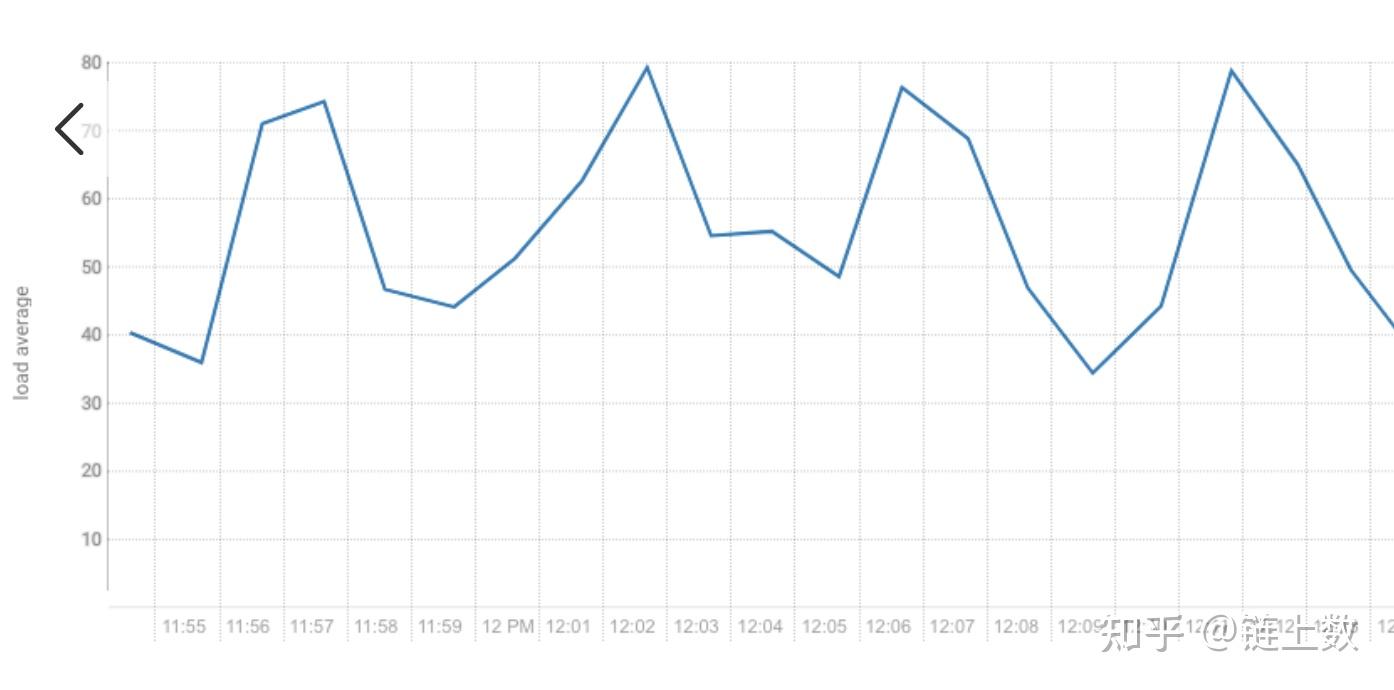
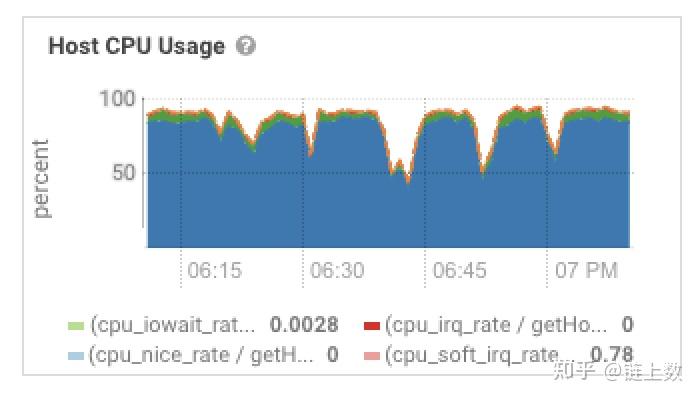
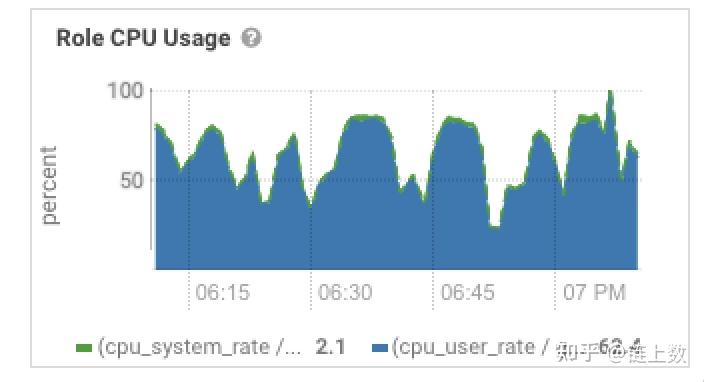
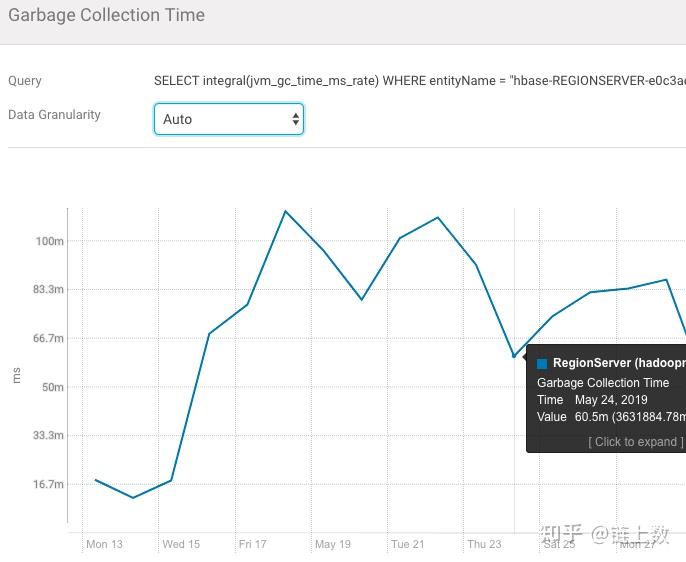
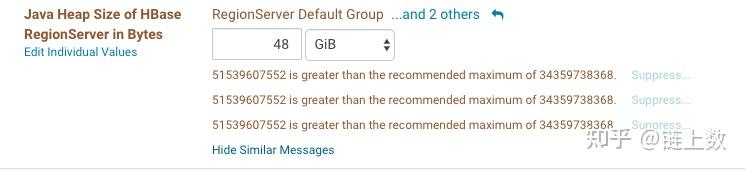
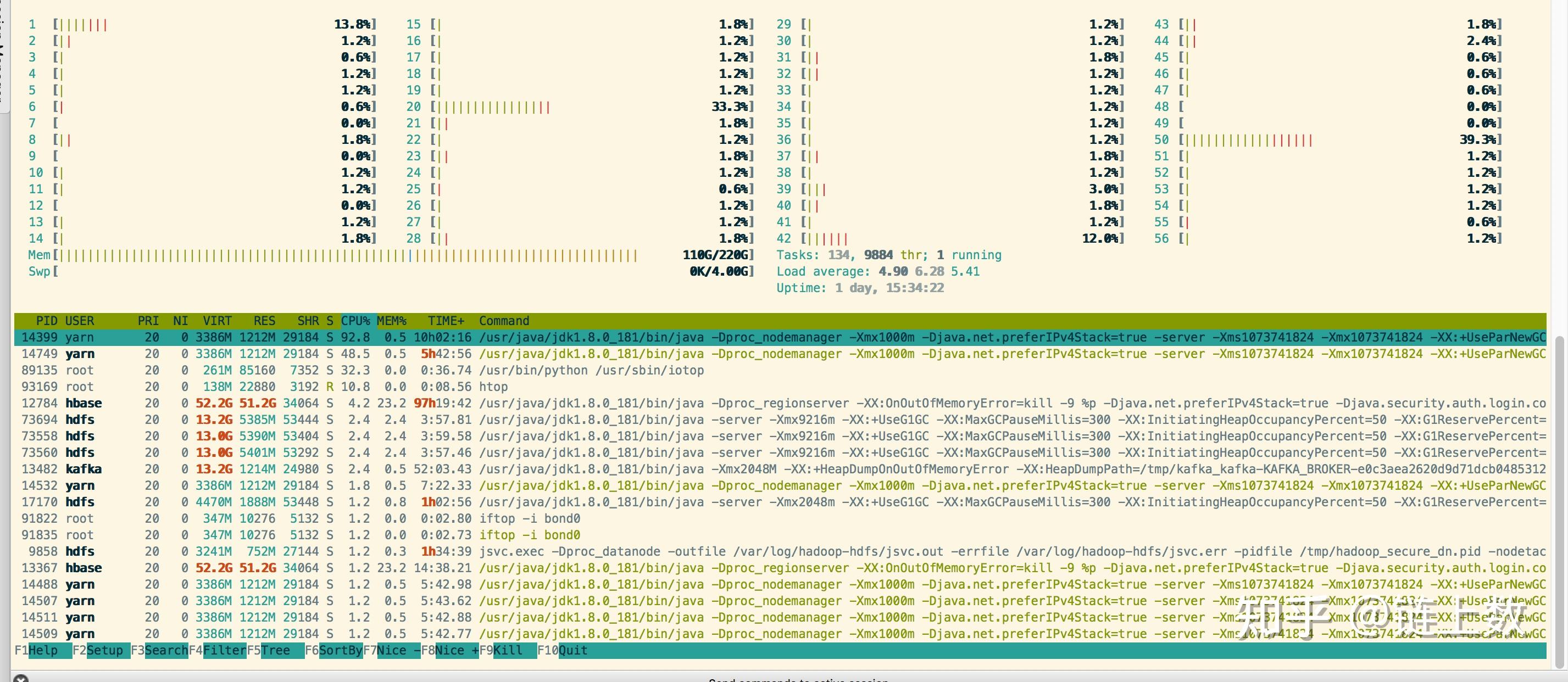
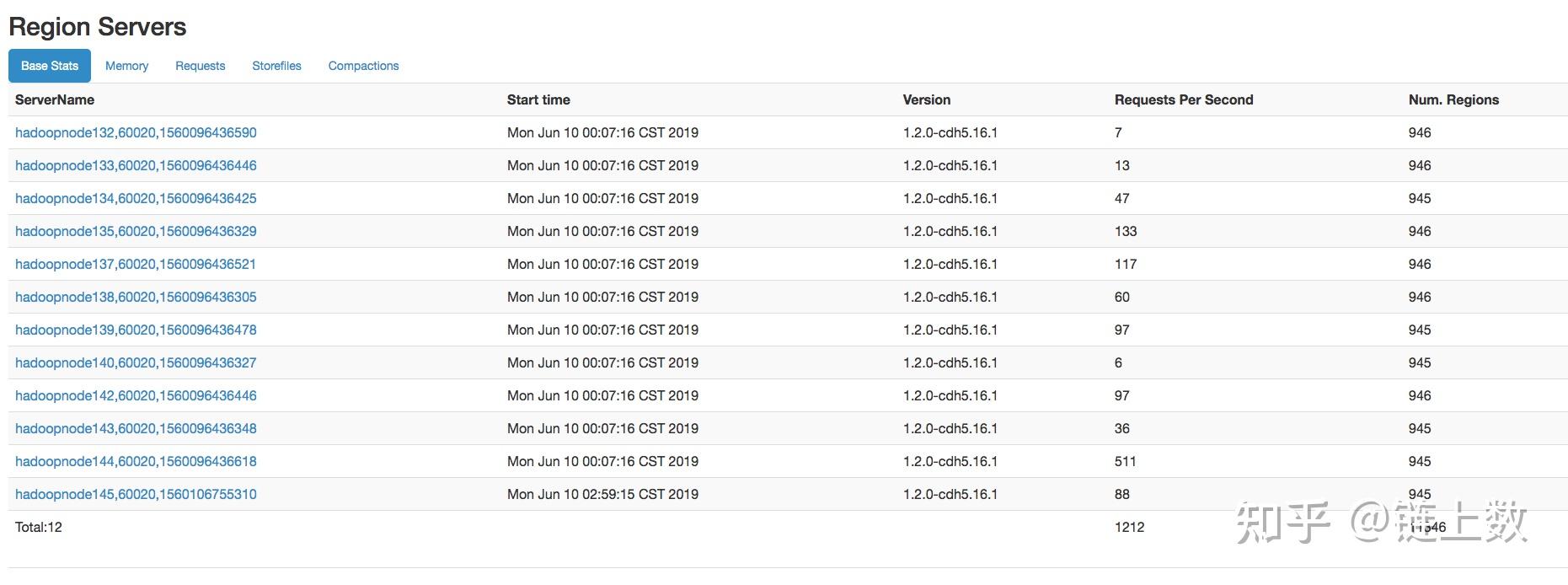
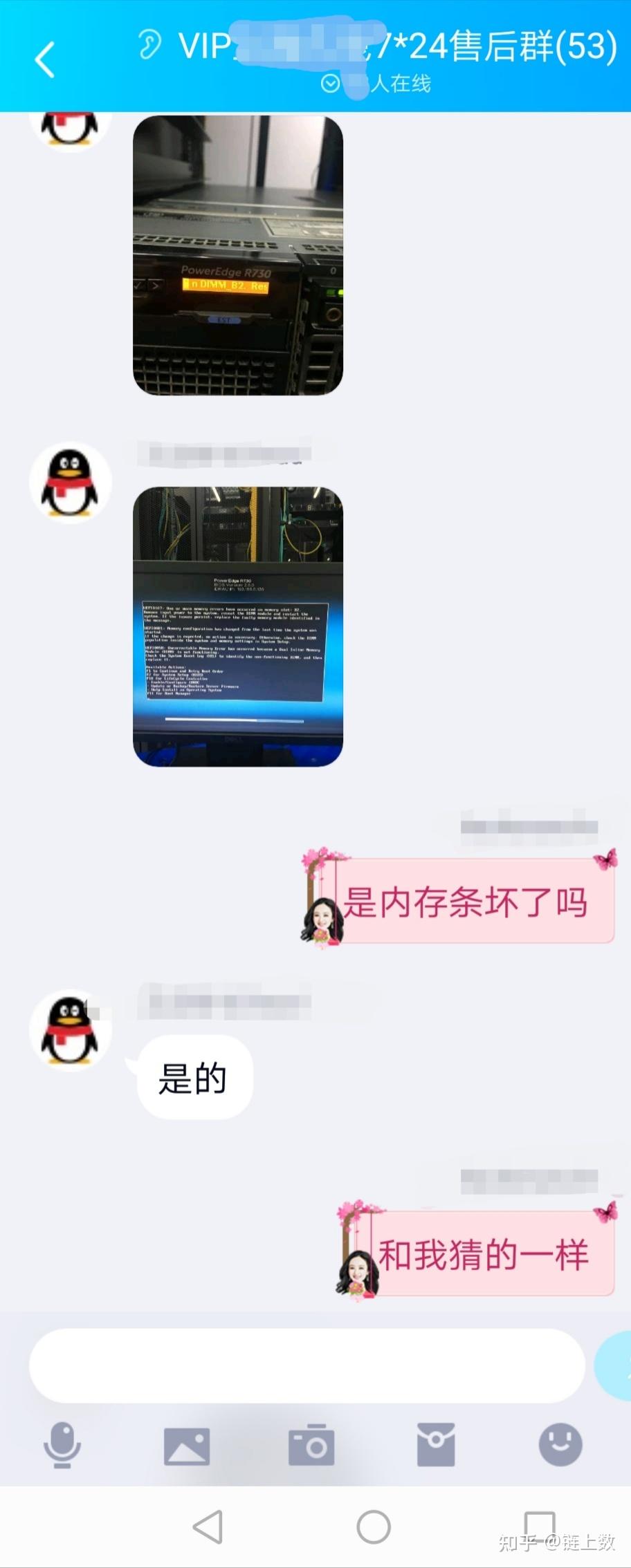
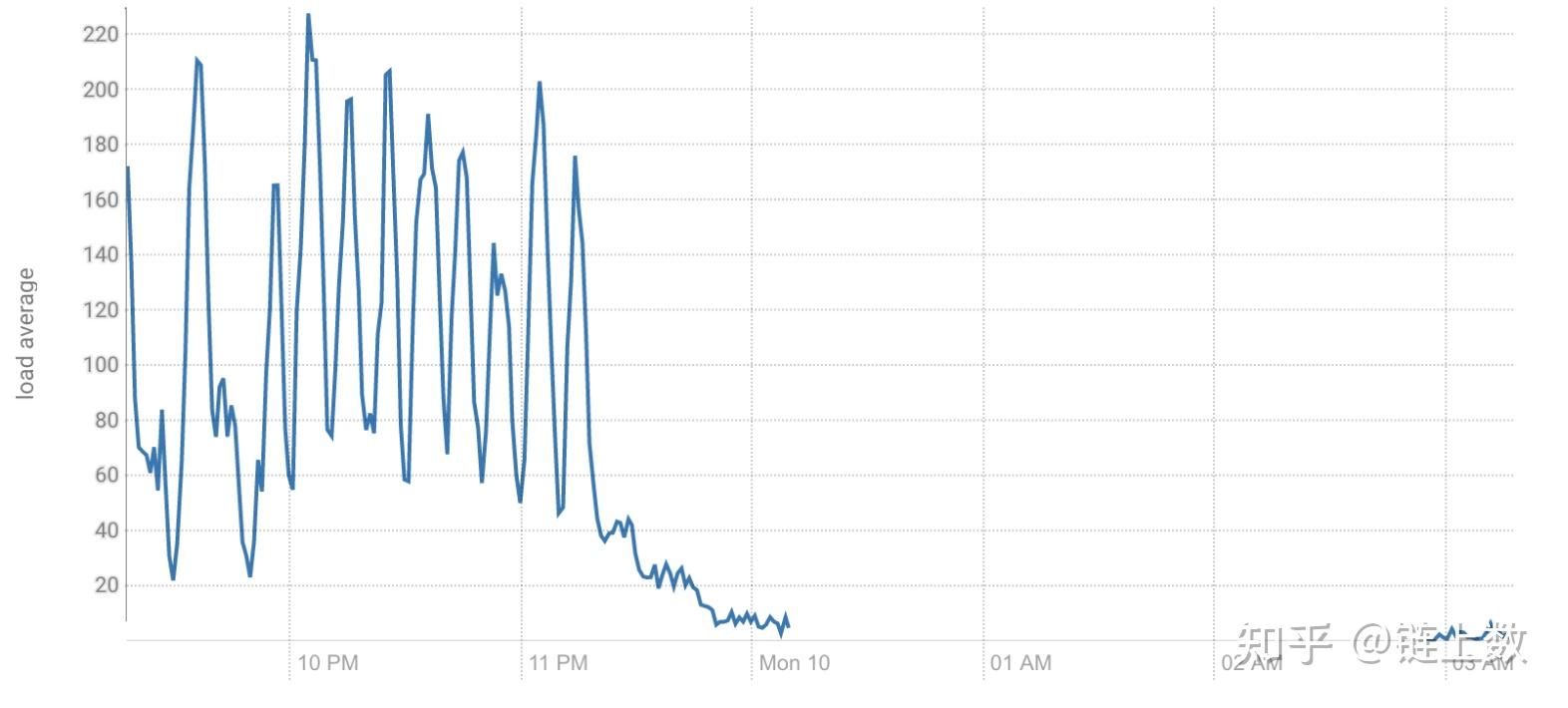
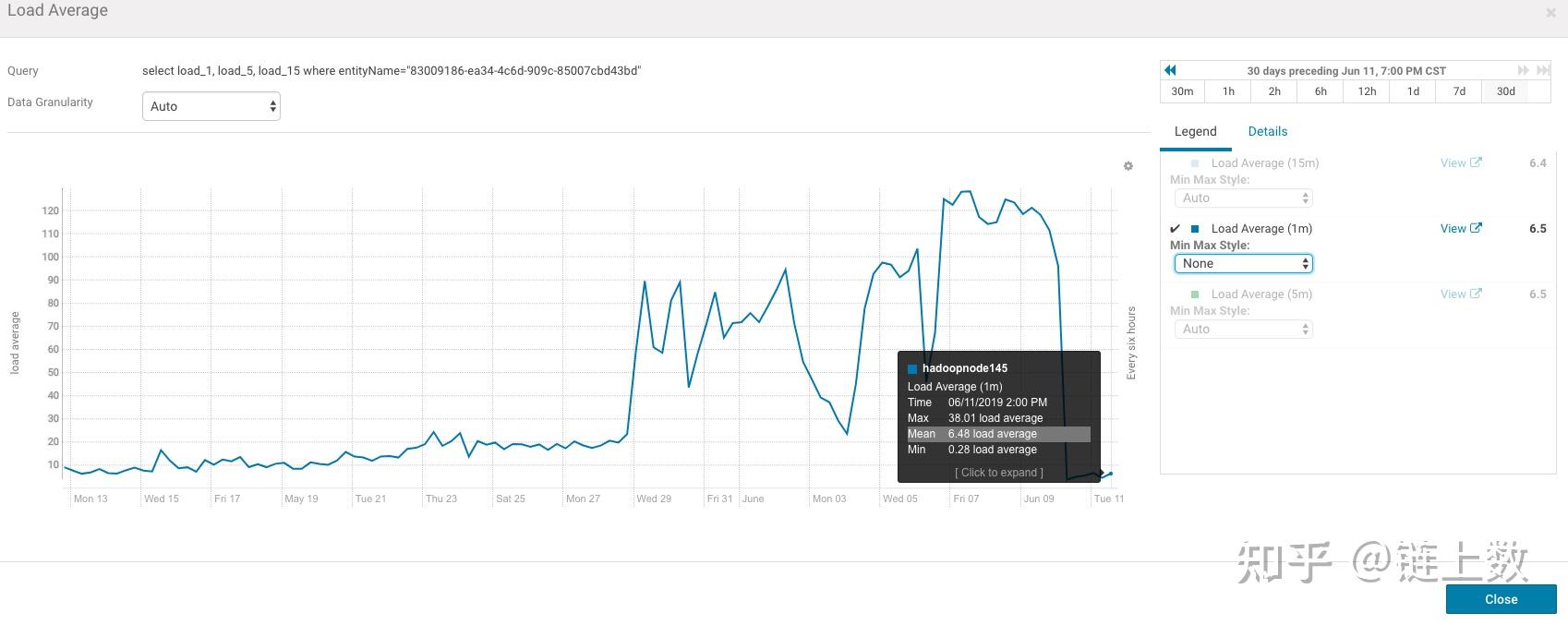
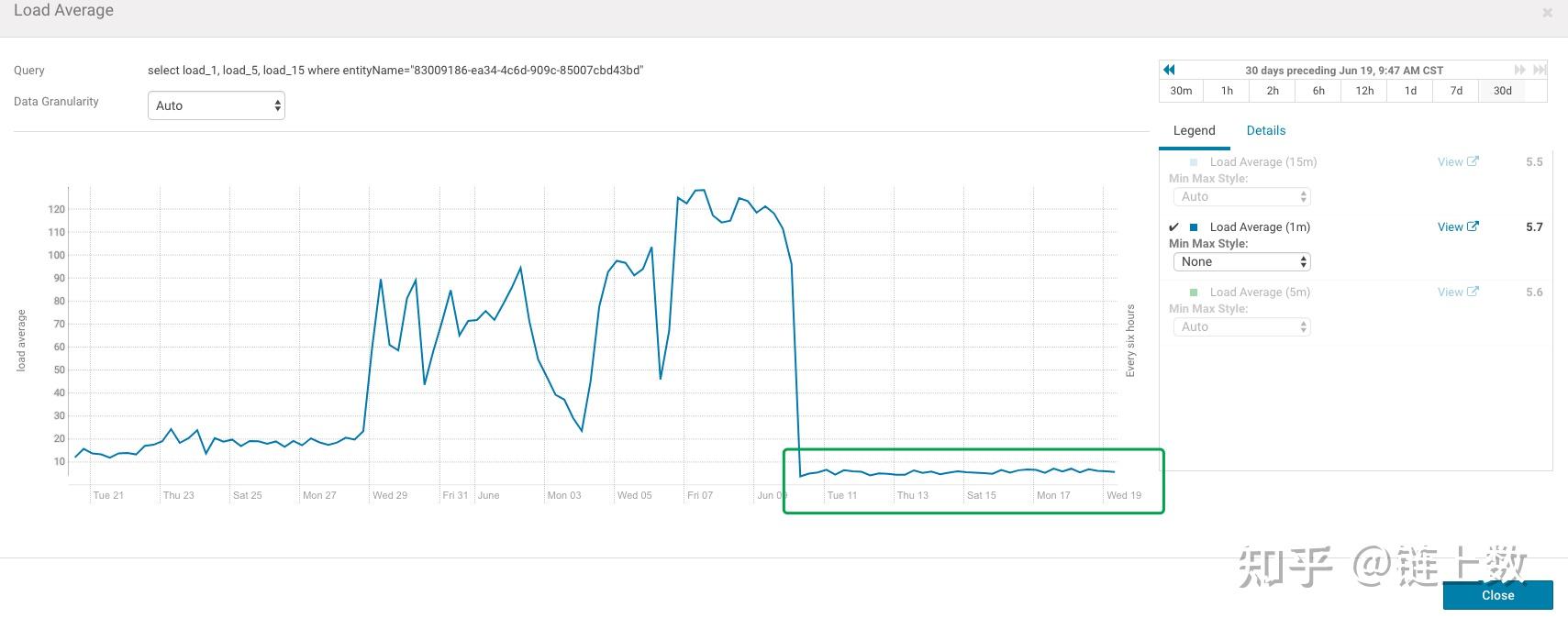
1.The health test result for REGION_SERVER_FLUSH_QUEUE has become unknown: Not enough data to test: Test of whether the RegionServer's flush queue is too full.
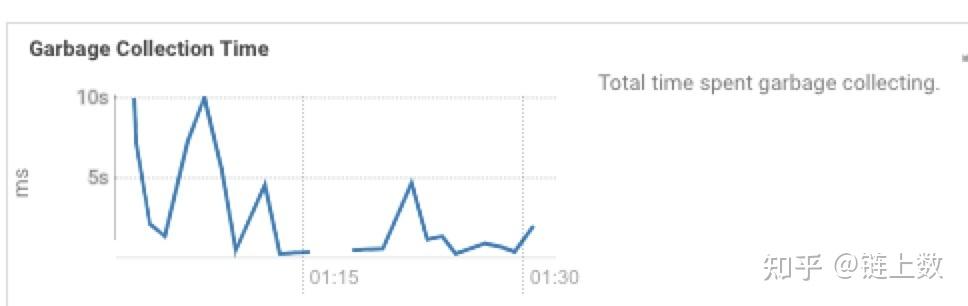
2.The health test result for REGION_SERVER_COMPACTION_QUEUE has become unknown: Not enough data to test: Test of whether the RegionServer's compaction queue is too full.



 发表于 2022-12-7 20:06:09
发表于 2022-12-7 20:06:09