|
|
在一个软件系统的运行过程中或多或少都会因为一些问题发生跳出正常业务流程的情况。通常这些导致跳出正常执行流程的问题被我们称为异常,而对异常的处理流程我们称为异常流程。
然而,经过一些年的编码实践后我们会发现,这些导致系统跳出正常流程的问题是多种多样的。
- 有些是可以被预见有些则不可预见,可以预见的可以根据问题产生的特定条件和对系统的影响设计相应的应对方案,不可预见的则只能通过捕获记录运行时上下文信息再来分析具体原因寻找解决方案。
- 处理流程有些可以直接将问题描述反馈给用户,有些则只能由系统记录或尝试其它执行流程。
面对如此复杂的问题域我们仅以一个单一的异常概念对其进行建模设计,是否可以应对所有甚至大多数场景呢?对于较小型的系统应该问题不大,如果是中大型的系统估计就会比较难了。所以,在稍微上点规模的系统中我们时常就会看到非常多的异常类型定义。在我们实际的系统设计和研发过程中,可以如何去建立起一个合理、优雅的异常管理体系呢?以下分享一些我个人的思考和理解。
概念探讨
在大多数编程语言中对于异常所提供的都是 try catch 的异常捕获处理机制。语言提供的只是一种处理工具,个人认为在实际系统设计过程中我们应该根据自己的业务和系统的特点建立自己的异常体系,然后再结合语言所提供的语法特性加以实现。
首先最基础的,我们可以把所有可能导致业务跳出正常流程的问题划分为两大类概念:错误和异常。(使用过 Golang 的人都知道在 Golang 中正是以这两个概念来提供对异常的处理机制。)以下是我对这两个概念的理解:
错误
错误是由于外部输入导致内部流程无法按照设计正常执行的情况。在设计和实现系统时我们已经识别到错误可能会不可避免的发生,所以在设计时就已经为这些识别到的错误提供了一些发生后系统相应的处理流程。所以,对错误的识别和处理设计应该是系统完整设计和实现的一部分。当我们为系统提供了足够多的错误处理流程后,用户使用系统就会更流畅从而获得更好的体验。
异常
异常是由于内部流程因为未识别到的问题,导致业务无法正常执行的情况。在设计和实现系统时无法预知异常会发生,所以无法为异常预先设计相应的处理流程,只能通过捕获、记录然后再通过分析处理来修复。因此,发生异常通常情况下就意味着系统存在 BUG。
概念分析
错误和异常发生的诱因
- 错误:由外部不可预知的输入导致。
- 异常:由内部未识别到的问题导致。
所谓外部和内部在不同的粒度下是相对的,所以错误和异常在不同粒度下也是相对的,例如:
在一个函数的粒度范围内:
错误输入是由调用方提供的,函数应该返回错误;而对于调用方来说,由于调用方自己并没有识别到它给别的函数提供了错误的输入,所以被调用方返回错误时对调用方来说应该是一个异常。
这样,当我们捕获记录异常日志后通过调用链追踪可以很快到达产生异常输入的节点,而不是先到接收到异常输入的点然后再反向追溯异常数据是如何产生的!
在一个接口的粒度范围内
一个接口的输入是由客户端所提供的,所以在接口的粒度范围内应该返回错误。而对于客户端来说,提供给接口的数据可能来源于用户输入再由客户端包装后提供给接口。所以,客户端可以借由接口返回的错误描述,判断错误是否由用户输入导致?如果是则将错误继续传递给用户;如果不是则说明是客户端内部存在不可预知的异常。同样,在进行异常追踪的时候我们只需把问题定位到客户端上,而不需要先查看接口日志再来判断是否是客户端提供了非法输入。
可预见和可修正性
- 错误: 具备明确的诱发条件具有较强的可预见性,并且可以通过修正输入修正。
- 异常:诱发条件多样,很难断定在什么情况下会以什么形式发生,很难提供正方法。
对于错误因为具有较强的可预见性,所以在设计和实现系统的时候,我们可以通过重点分析输入信息可能出现的各种情况,从而设计出相应的应对方案。例如:用户注册时最终用户可能提供不唯一的用户名,我们知道这有可能会发生并且不可避免,那我们可以设计当用户输入了不唯一的用户名时提示用户换一个重新输入。
而对于异常我们通常不太清楚它会在什么情况下会发生,所以设计时很难为其提供一个具体的解决方案。例如:网络异常我们知道它有可能发生,但我们无法预知它什么时候由于什么原因会发生:它可能是光纤被挖断了也可能只是偶然的网络抖动。这种情况我们无法预先设计一种肯定能解决问题的具体方案,只能提供几种可能解决问题的尝试方案。例如:切换线路重试、过一会重试。
系统设计
有了以上明确的错误和异常概念的建立,我们就可以用这两个概念作为主线来设计我们的错误和异常体系。
静态类型设计
首先,在类型系统中我们可以在最高抽象层级定义出错误和异常两个抽象类型:
- 错误:由调用方提供了超出预期的输入导致,需要调用方修正输入再进行重试。
- 异常:由于内部发生不可预知的问题所导致,需要记录问题发生时的上下文信息由开发或运维人员分析处理。
然后,在这两个抽象类型的基础上可以结合业务定义一些次级抽象类型。例如常见的错误类型有:
- 输入参数错误:调用方没有提供符合约定的参数类型、参数值范围或格式。
- 授权错误:调用方没有获得被调用资源的权限。
- 通信协议错误:客户端没有按照约定的通信协议向服务端接口提供接口数据(接口的角度)。
常见的异常类型有:
- 网络异常:无法通过网络获得远端服务的响应。
- 数据异常:从持久化设施中获取到超出预期的数据(被调用方没有返回错误,但返回的数据不对)。
- 配置异常:系统部署时没有提供正确的配置信息。
最后,基于这些次级抽象的错误和异常类型,各业务组件还可以定义出一些更具体的类型描述,最终形成一颗具有两个主干的错误和异常类型树。
动态流程设计
静态类型设计描述了我们错误异常体系的样貌,而动态流程设计则是叙述软件运行过程中错误和异常的运作模式。
在软件运行过程中如果一个调用节点发生错误,那么被调用方应该将错误信息反馈到它的调用方。而调用方接收到错误信息后,应该判读错误是否是由再上一级调用方输入的信息导致的?如果是则继续将错误信息向上进行传递直至产生错误信息的源头;如果错误不是由上级调用输入的信息导致,那么说明当前节点的逻辑中存在不可预知的问题,应该立即抛出异常。最终异常应该被异常捕获机制捕获并记录提供给开发或运维进行分析、修复。
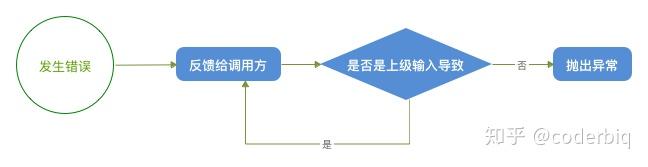
根据这个流程错误和异常信息到达最终用户的时候只会存在两种情况:
- 由于用户的输入导致了错误的发生,需要用户调整输入后重试。这种情况需要向用户提供尽量详细的错误描述信息以便帮助用户修正输入。
- 由于系统内部任何一个调用节点发生未知的问题产生异常。这种情况只需要让用户知道操作没有成功,他接下来可以如何尝试,不需要提供过多故障的细节信息。
编码实现
在使用某一门编程语言具体实现的时候,大部分的工作可能主要是根据业务定义具体的错误或者异常类型,然后再结合特定语言的语法特性来进行错误信息的传递和异常的抛出。在当前主流的编程语言中主要都是使用 try ache 的机制(有些语言可能关键字不一样,但机制类似),就像以下代码:
try {
$user = $userRepository->find($username);
} case (Error $e) {
if (e instanceof NotFound) {
return $e
}
throw FindUserException::fromUsername($username);
}
也有些语言提供了另外的语法特性来提供相应的支持,例如Golang:
user, err := userRepository.Find(username)
if err != nil {
if _, ok := err.(NotFound); ok {
return err
}
panic(FindUserException{Username: username})
}
总结
错误和异常处理是一个软件系统必不可少的一个环节,处理的好用户可以流畅使用系统获得比较好的使用体验,处理不好一但发生错误或异常用户操作就会被柱塞影响使用体验甚至无法使用。所以,我们在设计开发正向业务的同时也应该更加重视错误和异常流程的设计和实现。但是,在我接触到的一些研发团队特别是创业团队,或是因为资源的限制;或是没有意识到错误、异常处理的总要性;或是尝试了因为问题域比较复杂始终没能建立完善的处理体系。在系统上线之初甚至很长一段时间内都存在各种因为错误和异常处理不当引起的体验差、不可用等问题。所以,以此文和大家聊聊我对这个问题的看法和一些思考,希望对各位有所帮助。如本文表达的观点有不当之处还望各位指出。
最后,系统设计没有绝对的银弹只有比较适合自身情况的方案,希望本篇内容可以为你设计自己的异常体系提供一些有价值的参考。 |
|



 发表于 2022-9-20 17:04:44
发表于 2022-9-20 17:04:44

