|
|
Ampere架构作为NVIDIA在2020年推出的一款Tesla系列的GPU架构,是Turing架构后的新一代数据中心和图显架构。作为一款多用途的GPU架构,Ampere在图形处理和数据运算领域开始发挥其重要价值。本文主要带大家了解Ampere架构硬件的特点(第三代Tensor Core、稀疏操作、MIG等),并对A100 GPU进行功能实测,通过与V100进行对比,用实测数据让大家进一步认识A100的性能。
Ampere架构作为Tesla系列一员,是Tesla系列推出后的第八代GPU架构,读者可以先了解一下Tesla的发展历史:
例几个读前问题:
- Ampere架构的变化相比Volta 模块上面有无增减?
- 第三代Tensor Core相比第一代主要的主要的变化是什么?
- A100的Tensor Core 如果只算FP32的FFMA,和第一代(V100的)差距有多大?
- A100对FP64支持如何?Ampere之前的架构能完成FP64运算吗?
- A100硬件上支持哪种稀疏操作?
- MIG是独立子GPU还是虚拟GPU?
- 异步拷贝操作有什么优势?
1 Ampere架构产品与资料
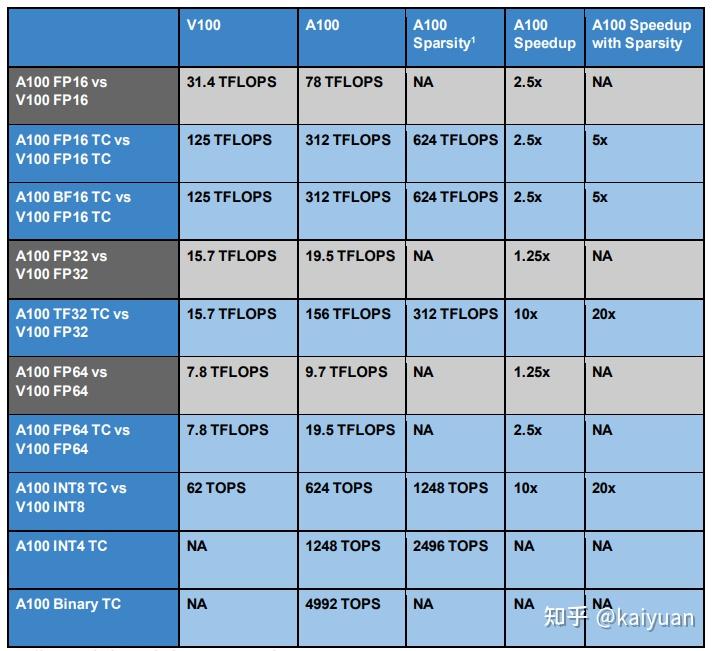
英伟达(NVIDIA)公司对市场发展动向有着敏锐的嗅觉,其近几年的产品能够很好地满足市场的需求。对于近几年热门的行业(AI/自动驾驶/虚拟现实),英伟达在硬件上面做了针对性优化设计。比如深度学习、高精度运算等需求引导了Ampere硬件设计的方向,最明显的就是它的Tensor core的改进,不仅支持一些新的精度操作而且还支持稀疏操作,很明显这个对深度学习运算是非常有帮助的。如下图所示,--A100的Tensor Core在不同数据上面的计算速度的对比:

Ampere架构的产品同时兼顾了企业与普通消费市场。在企业用户上,目前A系列的数据中心GPU卡已成为很多厂商采购的首选产品。目前在国内尽管A100受到了一些销售限制,但A100 GPU的规格在各个云厂商上面基本都有提供;同时在普通消费(图形/游戏)方面,该架构也有对应的GeForce产品RTX 30系列,并且相比前一代Turing架构的20系列性价比近乎翻倍,Ampere产品也受到了消费者的青睐。
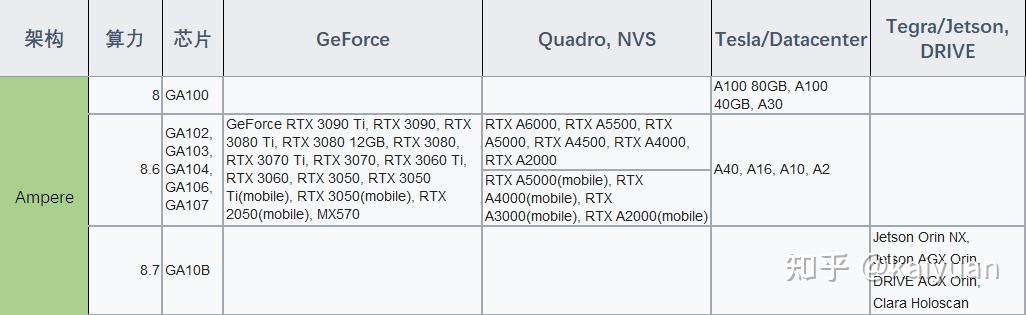
相关资料:
对于Ampere架构的资料阅读,如果是数据中心用户,比如A100、A30 ,可查看GA100芯片的白皮书:【Ampere架构 GA100白皮书】;如果是消费用户,比如RTX30系列,查看GA102芯片的白皮书:【Ampere架构 GA102白皮书】。其它资料:
- 【A100特性手册】:“NVIDIA A100 TENSOR CORE GPU”;
- 【A100 80G pcie产品】:A100 80GB 的产品介绍;
- 【A100 40GB规格pcie产品手册】:产品介绍;
2 参数与特性分析
Ampere架构相比上两代架构,基本特点概括为:算力更强、通信更快、显存更大,支持虚拟化。
- 算力:新的SM采用第三代Tensor Core,其数据运算速度提升、支持直接操作的数据类型变多、增加细粒度结构化稀疏操作。
- 通信:主机-显卡采用PCIe4,同时支持虚拟化(SR-IOV);显卡间通信采用第三代NVlink,带宽600GB/s、通道12,相比上一代速度翻倍;卡内通信速度增加:HBM2 带宽相比V100增加0.73;支持异步拷贝操作,全局内存数据通过L2可直达共享内存。
- 显存:全局显存规格提升到40GB / 80GB,L2存储规格40MB, 共享存储可配置164KB/SM
- 虚拟化:推出MIG特性,支持实例划分,支持7个子GPU实例的创建。
- 其它:改进错误处理方式,局部处理替代整卡重启的方式。增加异步barrier操作。为深度学习增加JPG解码引擎。
本文中Ampere架构特点分析我们主要以GA100芯片为主展开进一步讲解。
2.1 主体架构
Ampere架构芯片采用了7纳米工艺(TSMC 7nm N7 FinFET),相比V100的12纳米工艺,相同面积上面能够承载更多的元器件,一个全量的GA100芯片,包括如下的单元:
- 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs/GPU
- 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores/GPU
- 4 x Tensor Cores(三代)/SM, 512 Tensor Cores/GPU
- 6 HBM2 stacks, 12 x(512-bit) Memory Controllers
- NVJPG x 1,OFA x 1, DEC x 5
2.1.1 架构与参数
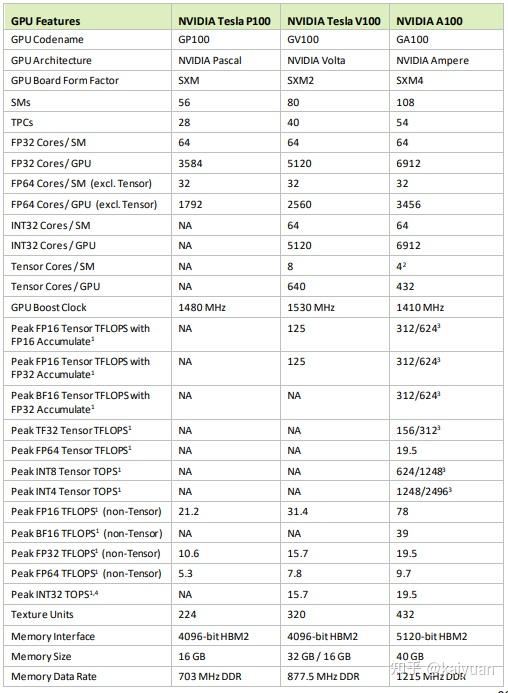
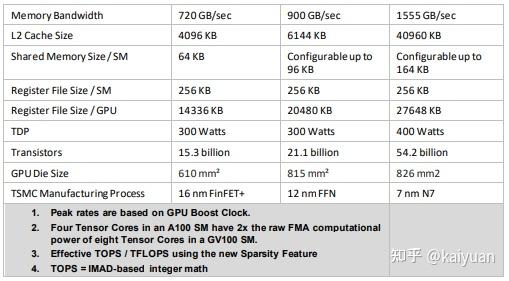
GA100芯片在A100 GPU上面的原件数量有所减少,主要参数:108 * SMs,432 * Tensor Cores,5 * HBM2 stacks,10个内存控制器。相比P100和V100这两款数据中心的GPU,A100支持的操作数据更为丰富、存储空间更大,对比参数如下所示:
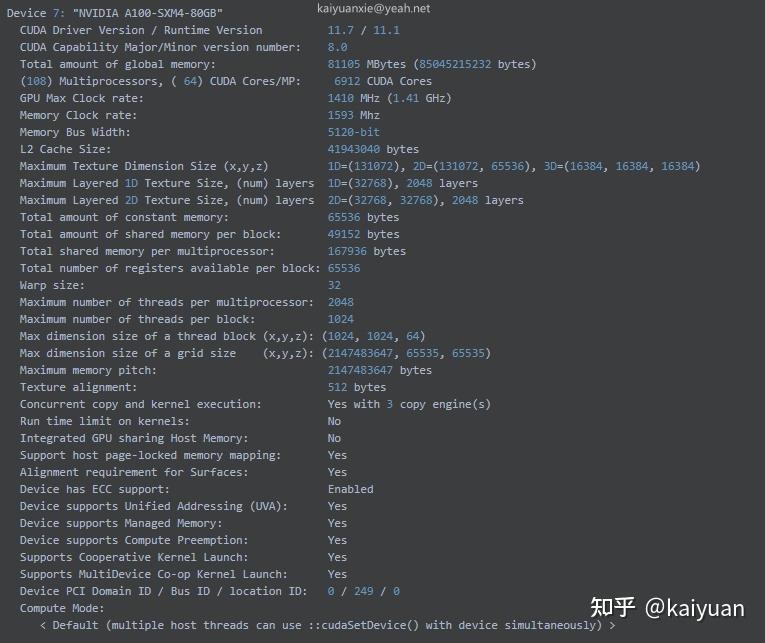
对于上述的电器参数的查看,可用CUDA里面的deviceQuery来查看一些主要电气参数,如下展示了查看“NVIDIA A100-SXM4-80GB”卡的信息的方法:
## centOS系统:
# cd /usr/local/cuda/samples/1_Utilities/deviceQuery
# make
# ./deviceQuery
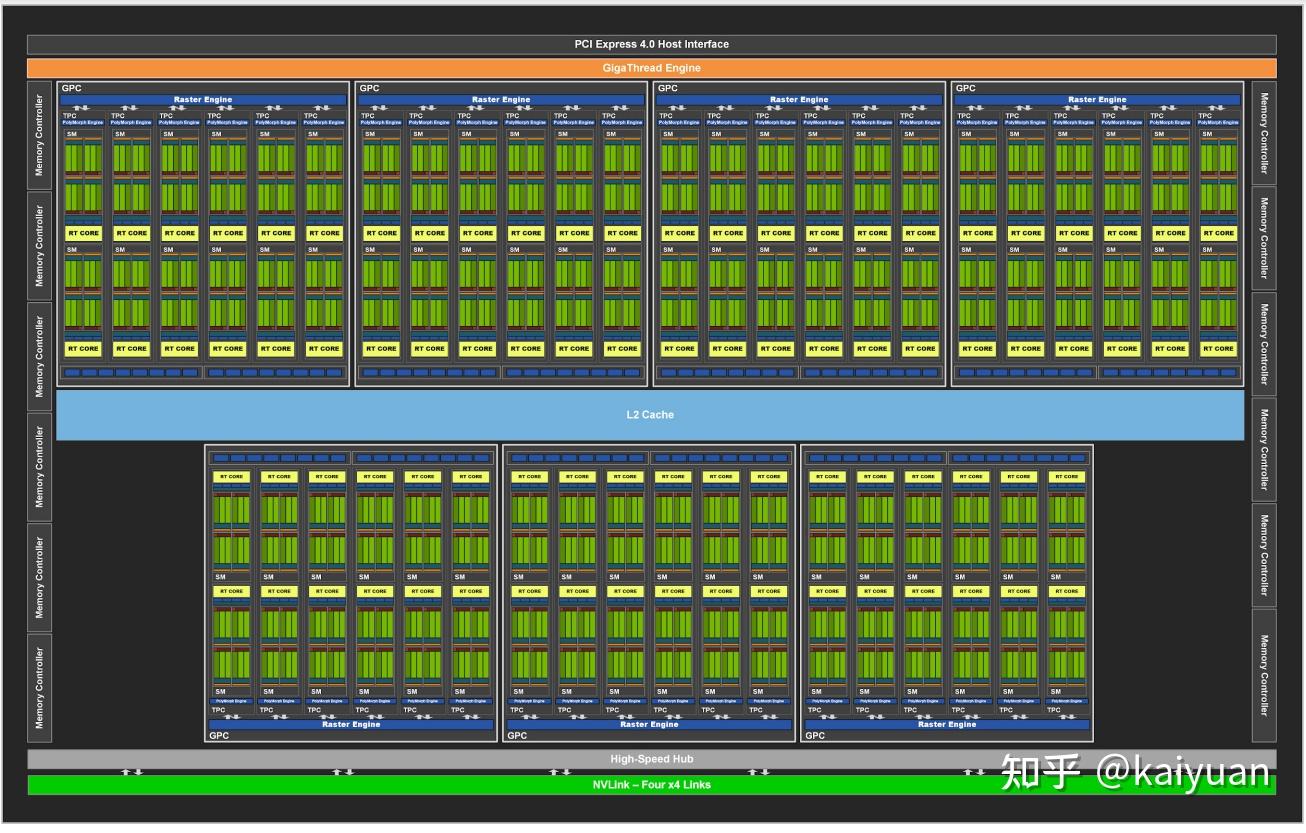
GA100 全量GPU 卡的架构图如下所示,元器件的数量与Volta架构相比,有所增多,其主体内容变化不大。主要的差异点是:
- Giga线程管理器(Giga Thread Engine) 里面多了一个MIG控制器;
- L2 cache 分了两段(不确定实际的印制板上面是不是也分开了);
- 周边存储管理器(Memory Controller)和P2P通信(NVLink)元件数量增多了。

其它硬件模块:
- DEC/ENC:NVDEC/ENC是视频加解码引擎, GA100配有5个DEC。
- JPG: GA100里面有一个NVJPG 解码器,这个能够加速图片的解码速度。将JPG图片的解码工作从CPU转移到GPU内完成,能够极大提高某些场景(如深度学习读图片)的速度。
- OFA:GA100里面有一个光流加速器(OFA,Optical Flow Accelerator)硬件模块,能够提高光流和立体显示的速度,适用于CV场景。
相比GA100芯片,GA102图像芯片的主体架构的SM(x84)数量和CUDA core的总量都偏少。由于GA102是图形化芯片,所以会多配备PolyMorph引擎,在GPC里面配备有ROP(x 2)、Raster引擎,每个SM里面配备了一个二代的光追踪引擎(RT Core),GA102的架构图如下所示(本文不对GA102做详解)。
2.1.2 SM结构
GA100芯片的SM相比上一代的SM在结构上面主要的改进点是Tensor Cores,其算力和支持的数据类型都得到了提升。SM的架构图如下所示,一个SM 里面有四个相同的单元,每个单元包括独立的L0指令缓存、Warp调度器、Warp执行器、寄存器、INT32 CUDA Core、FP32 CUDA Core、FP64 CUDA Core、 Tensor Core,以及特殊运算单元SFU、数据加载保存单元(LD/ST),SM里面还有L1指令缓存和L1数据缓存,以及四个Tex处理单元。其中L1数据缓存是可配置的,能够作为Shared Memory使用。
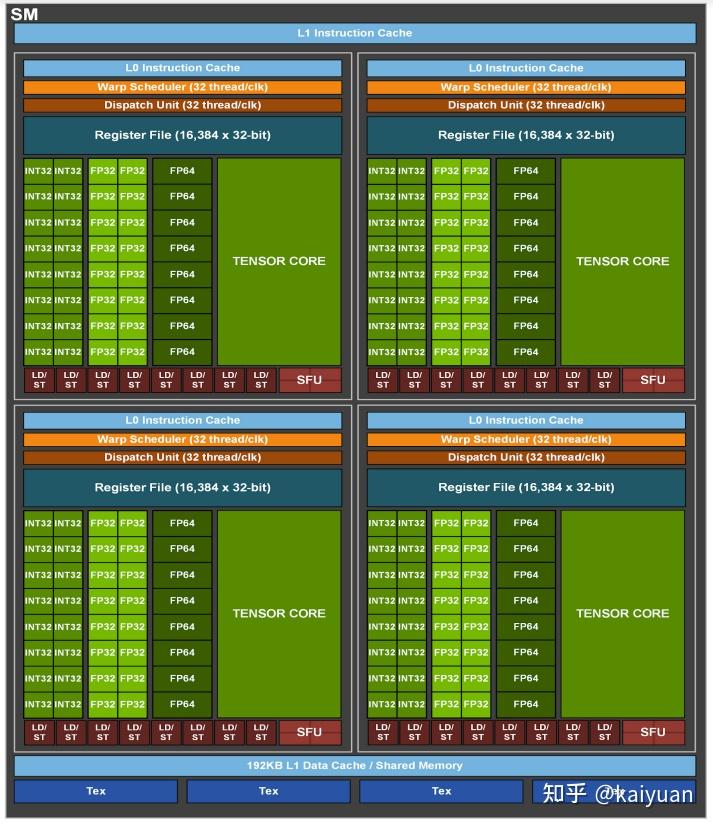
从架构上面能够直观的看到,变化较大的是CUDA Core,CUDA Core对于高精度的处理单元数量会增加,所以对应的能力会明显增强;而Tensor Core相比之前的Volta(8个),数量只有4个,但计算能力提高了不少。
SM配备了第三代Tensor Core,主要特点:
- 支持的操作:FP16, BF16, TF32, FP64, INT8, INT4, 和 Binary.
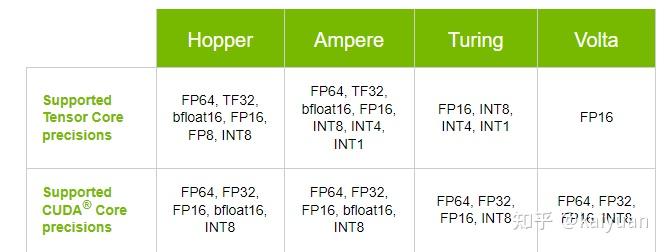
- 支持稀疏操作;
- BF16/FP32 混合精度计算速度与FP16/FP32混合精度计算速度相当;
- FP64的DFMA操作比V100快2.5倍;
- 在DL(深度学习)方面的FP32计算、INT8计算均有所改进。
SM的其它硬件改善:
- 共享内存与L1缓存共用192kb空间,是V100 1.5倍;
- 全局内存-> 共享内存的异步拷贝,不需要借助L1缓存和寄存器,减少使用寄存器;
SM的软件改善:
- 共享内存支持异步阻塞和异步拷贝(cooperative_groups::memcpy_async)
- warp 内新增reduce操作指令(Warp Reduce Functions),这样能够调用指令,直接完成warp内的求和、求最大/最小值,以及逻辑操作。
2.2 Tensor Core(第三代)
第三代Tensor Core优化点:线程同时共享数据数量、warp指令、RF读写次数、运算周期。比如完成一个16x16x16的矩阵乘法操作,和FFMA、V100的TC(Tensor Core)作对比,其数据如下所示:
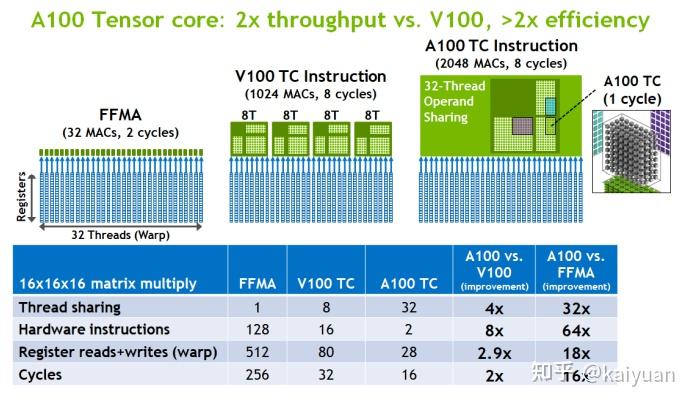
可以看到,相比V100的TC,A100的TC 运算时做到了warp内的数据共享,处理的指令数变少(16:2),所需运算周期也减少(32:16),对寄存器的读写次数减少(80:28)。
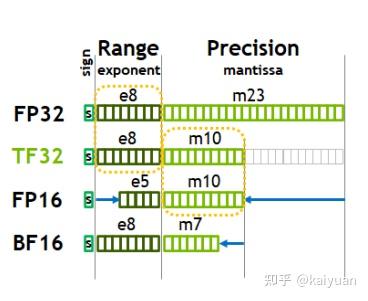
第三代Tensor core的操作数据比上两代更加丰富(V100仅支持的是FP32和FP16)。其中支持的浮点数据增加了BF16、TF32。对比FP16、FP32的表示方法(如下图所示),TF32与FP32有相同的指数位数,而精度位置进行了缩减,TF32小数位与FP16相同;BF16 相比FP32则是指数位相同,小数位只有7bit的记录数据。 A100还支持INT数据操作、binary数据操作。丰富的数据类型支持用户根据不同应用场景来选择数据,由于不同数据的运算速度存在差异,低精度的数据运算更快,从而带来了运算提速的可能空间。
第三代Tensor Core的数据支持还有一个值得注意的地方,就是对FP64计算的提速(这里说明一下是优化了FP64计算,而不是创造了新的FP64计算,也就是说Volta之前的架构也能进行FP64的计算)。FP64主要是在一些科学研究领域有需求,在一些应用场景下运算的精度越高越好,以往的做法是将高精度运算分解为多个低精度运算步骤完成。A100上面对FP64的硬件设计进行了优化,使得A100的FP64 计算速度是V100的2.5倍。
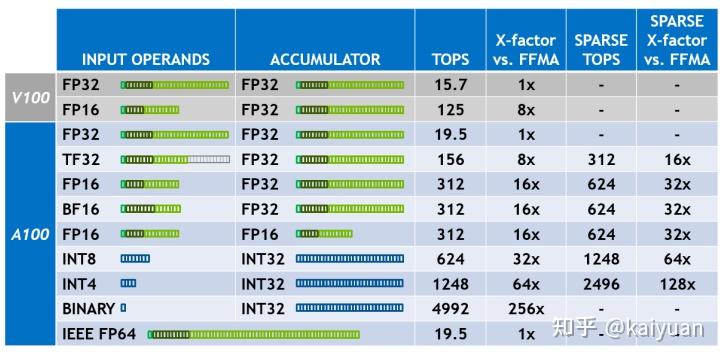
A100支持多种输入和输出的类型组合,这些组合能够带来不同程度的提速。如下表所示,以最典型32位浮点的FFMA运算(融合运算 先乘后加)作为参考,计算速度假设为1倍。可以看出,调整数据类型能让运算速度得到增加,若进一步将数据进行稀疏操作,运算速度还能得到进一步增加。
混合精度(降低精度)会带来运算速度的提升,同时需要考虑运算精度损失。在A100的白皮书中给出了如下的测试数据,测试数据1如下所示,基准线选取FP64数据,对比数据包括TF32-TC(Tensor Core)、FP16-TC、BF16-TC 以及FP32,纵轴是对比其它数据达到FP64相同精度所需要的迭代次数,负数表示无法收敛到FP64的精度。
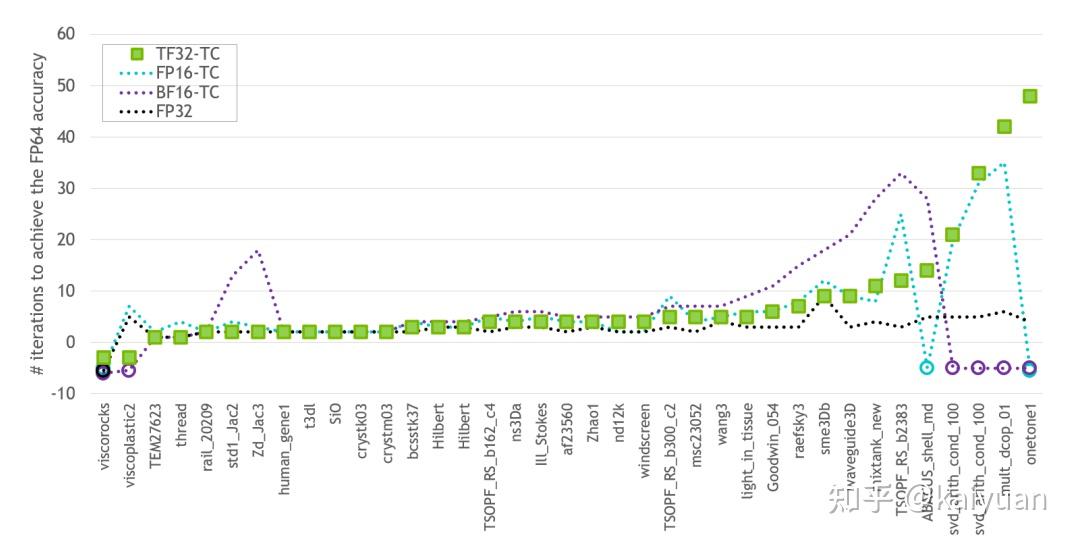
数据2如下所示,表示达到FP64相同精度的加速比,负数表示未收敛。从表可知TF32-TC有较稳定的表现,在各种场景中基本有加速。
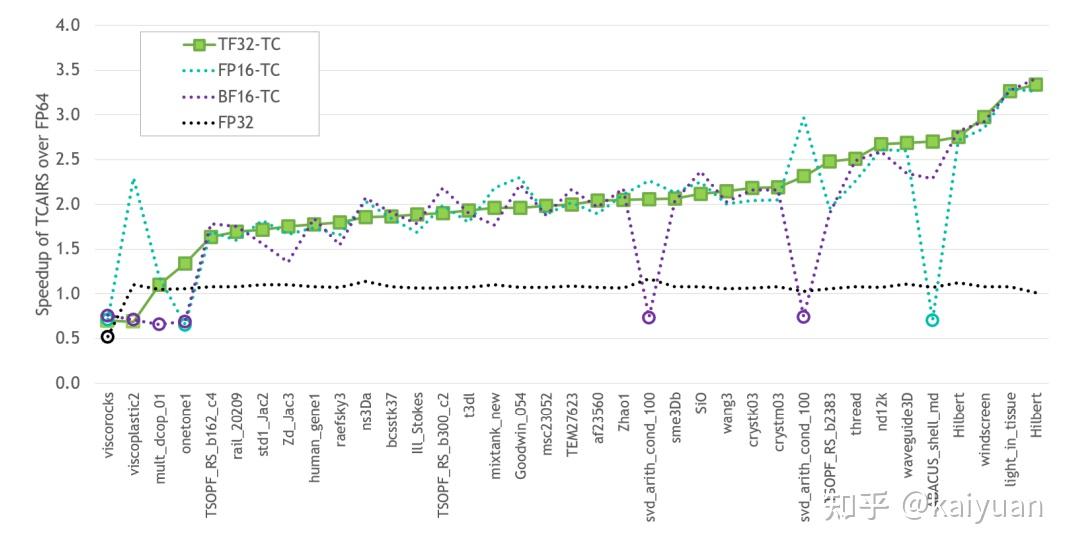
从测试数据中还需要知道,不是所有数据类型都会有加速;有的数据类型在某些场景下面加速不明显而且运算不收敛。所以需要根据具体的用户场景来使用低精度,并且在计算速度和精度中寻找一个平衡。
2.3 稀疏操作
针对深度学习的神经网络提速,Ampere架构增加了细粒度结构化稀疏操作(Fine-Grained Structured Sparsity),该操作能够使网络计算的吞吐量增加,显存消耗降低。
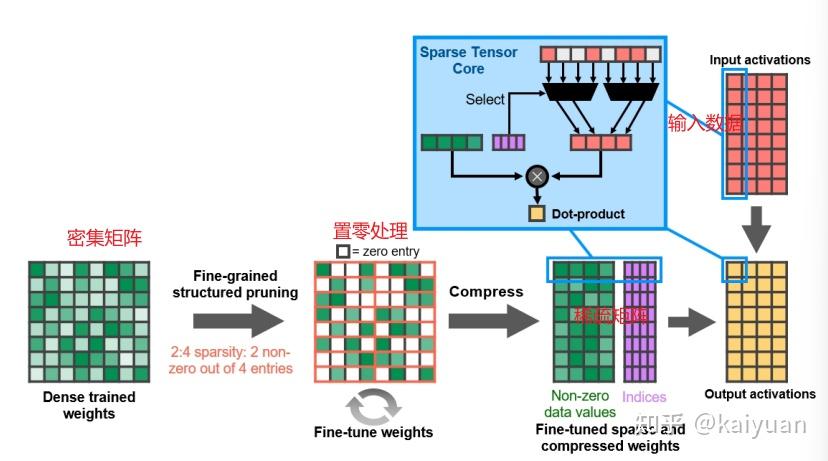
稀疏操作的理论是基于对“神经网络里面的一些数据置零后对精度影响可接受,不影响最终输出”的假设。A100推出了2:4的稀疏操作矩阵,即对输入的矩阵按照2:4的比例保留,剩余位数据直接置零。如下图所示,给出了一个深度学习中常见的权重运算,稀疏运算步骤如下:
- 对密集(Dense)矩阵按照2:4裁剪,获得裁剪后的权重(weights);
- 将权重进行压缩并用稀疏矩阵表示,表示方法是一个数据矩阵和一个索引矩阵;
- 根据索引矩阵对输入(Input)的数据进行选择(相当于裁剪);
- 将权重数据和输入数据进行点乘(dot)操作获得输出结果。
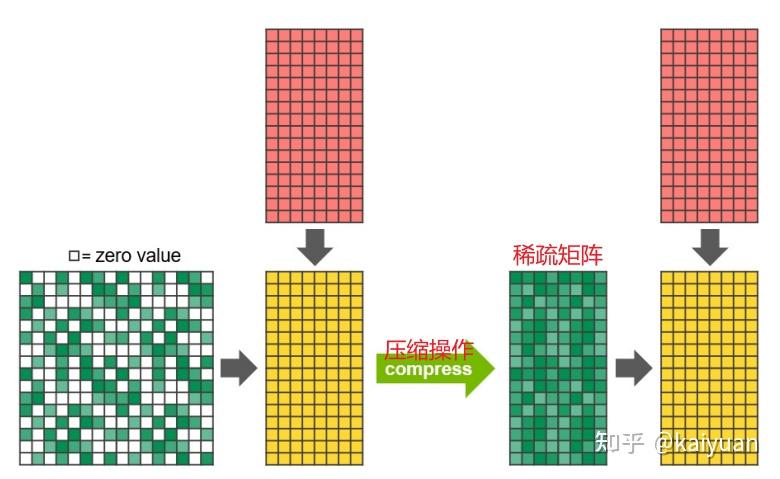
相比一般的MMA(Matrix Multiply-Accumulate,矩阵乘加操作)运算操作,A100支持稀疏化的MMA操作,通过2:4结构化的矩阵会产生许多非零值,稀疏化的MMA能够避免非零值的运算,从而提升运算速度。示例如下,完成一个矩阵A (16*16)和矩阵B(16*8)的运算,稀疏化运算能够跳过非零值,这样相当于把矩阵A 压缩到了(16*8)的矩阵大小;这样使得计算速度能够提升2倍。
2.4 MIG特性
MIG(Multi-Instance GPU)作为Ampere架构推出的GPU分割功能,解决了像Ampere这种大GPU在集群服务应用时一类需求。在此之前的GPU架构都是作为一个整体提供给上层服务使用,尽管有类似vGPU这种虚拟化的GPU满足了一些云服务厂商(Cloud Service Provider (CSP))的需求,但是由于没有从硬件层面设计支持GPU切分,使得虚拟GPU在数据保护、故障隔离独立、服务稳定方面都表现欠佳。
Ampere架构通过硬件上面的设计使得GPU能够创建子GPU(GI),GI在计算、内存带宽、故障隔离、错误计算、错误恢复方面都相对独立,其服务质量(QoS)能够较好的保证。MIG的基本方法(原理)就是能完成资源的分块+组合,即对物理卡上能用的物理资源进行切分,这些资源包括:系统通道、控制总线、算力单元(TPC)、全局显存、L2 cache、数据总线等;然后将分块后的资源重新组合,让每个切分后的子GPU 能够做到数据保护、故障隔离独立、服务稳定。
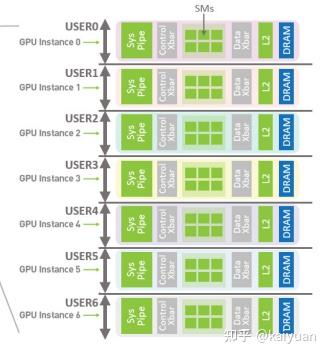
关于MIG由于内容比较多,所以单独写在了“MIG-GPU简介与A100-MIG实践详解”中:
2.5 存储与通信的改进
在GPU中存储主要是全局内存(Global Memory)、L2 cache、L1 cahce以及寄存器(RF)。A100在存储和带宽上面都做了改进,改进的手段有:
- 增加容量和带宽;
- 缩短数据链路(异步拷贝);
- 减少传输数据量(数据压缩);
相比V100其改进点如下所示,其中绿色表示存储大小提升,橙黄色表示带宽(BW)提升。

按照数据传输链路由外到内,依次看一下容量和带宽的变化:
- NVLINK:的带宽是V100的2倍,
- 全局显存DRAM:采用的是改进的HBM2,容量是V100的1.3倍(这里比的是A100-40G,A100还有80G的规格),速度是之前的1.7倍;
- L2 cache: 6.7倍容量,2.3倍带宽。容量增加能够支持更多经常访问数据(Persistence Data)直接存放到L2。比如通过常访问的数据控制(Residency Control)使得LSTM网络上的GEMM操作就可以在L2上面复用;同时,L2这个提升对MIG特性是非常必要的,要保证子GPU的切分的容量空间;
- SMEM: 共享内存的速度和带宽都有所提升,但是它与L1共用一个空间,意味着SMEM调大会降低L1的量;
- RF:可控制寄存器的空间变大。在拥有三代Tensor core 和异步拷贝(绕过寄存器)操作情况下,对RF的要求变低,所以相比V100的处理速度会提升。
- 图中Math是指运算操作;
- Tensor Core 以及稀疏操作的带宽与V100相比都有提升;
- 数据压缩操作(Compute Data Compression) 降低了数据量,可提升L2缓存的上下游的传输速度,同时降低对L2缓存的消耗。
2.5.1 异步拷贝和异步阻塞操作
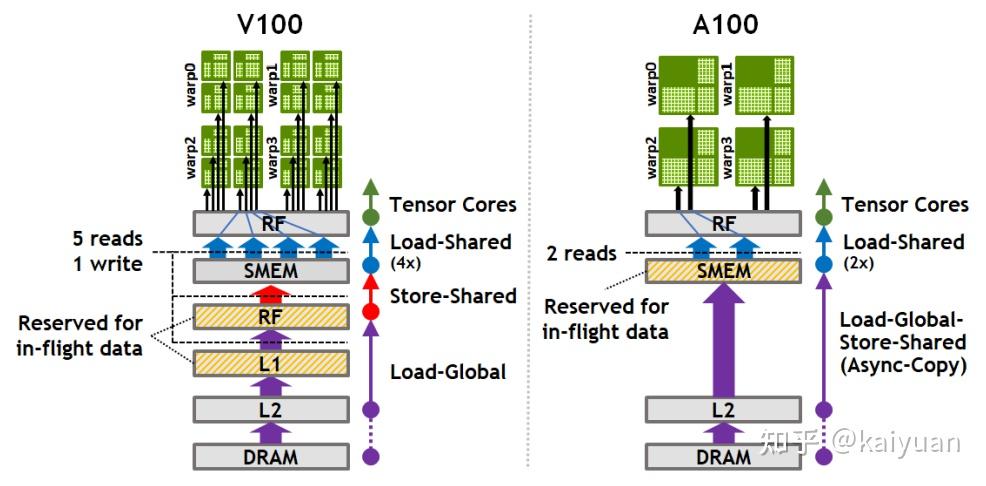
异步数据拷贝操作支持数据直接从L2缓存运输到共享内存SMEM上,这样可以缩短数据传输链路、同时降低内存的消耗。如下图所示,对比V100和A100共享内存数据传输的差异,在V100上面数据从全局显存DRAM到SMEM需要经过L2->L1->RF,而A100上面能直接从L2到SMEM。这样带来的好处是,减少了途径的存储设备、降低了L1 以及RF的消耗量。
异步阻塞(asyc barrier)操作,能够支持thread在所有线程抵达之前进行独立的处理工作。如下图所示,之前的同步阻塞,必须等到全部block中的所有线程都准备好了才会进行下一步处理,这样block里面所有线程占用的资源都会闲置,直到最久的那个线程准备好。 异步阻塞的工作机理是只要线程的数据准备好了就进行处理,不用等到所有线程都准备好,从而降低了资源的闲置时间。异步阻塞操作在数据拷贝时用处较大,能够释放闲置资源进行其他处理工作,提高了SM的效率。
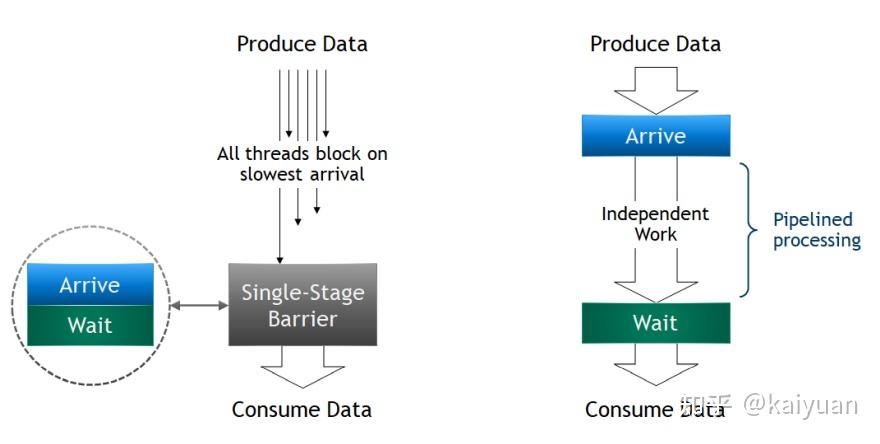
同步阻塞vs异步阻塞
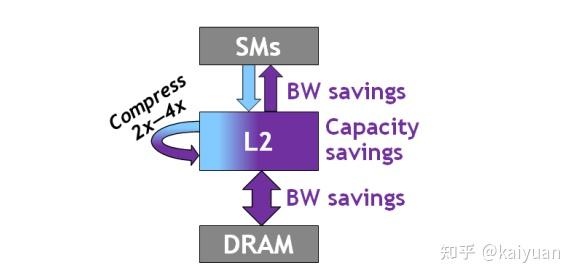
2.5.2 数据压缩操作
数据压缩(如稀疏)操作通过对全局显存上面的数据进行压缩,可以直接降低传输的数量,从而降低全局显存到L2的带宽占用、L2到SM的带宽占用,以及节约L2的空间。
2.5.3 数据故障处理
Ampere之前的架构故障的处理都是以整卡为单位进行处理,这样对上层应用来说,其相互之间存在一定的耦合关系,而要消除这些故障时可能需要重启整卡。Ampere架构在故障的检测、隔离、恢复都做了改进。故障的处理考虑到了多实例GPU的情况,Ampere的故障管理是按照应用来进行隔离管理,即每个应用实例产生的故障控制在该应用的内部,不影响其他应用的正常使用。这一点保证了MIG创建的子GPU之间相互不影响。
对于存储方面的检测与恢复,ECC的覆盖范围比之前的更大,单精度检测恢复和双精度检测的ECC支持了L2、L1以及RF。
2.5.4 NVLink
作为GPU之间的专用通信通道NVLink已发展到了第四代,A100上面装备的NVLink是第三代,通信带宽能达到600GB/sec,通道数量12(每个通道提供25GB/sec的单向带宽)。相比PCIe通道,NVLink的速度已经超过10倍,采用NVLink不仅能够释放PCIe的占用,而且对卡间的数据交换帮助也极大。对应的NVSwitch升级到了第二代,能够让节点上的卡之间保持最高速度通信,总带宽:2.4TB/s。
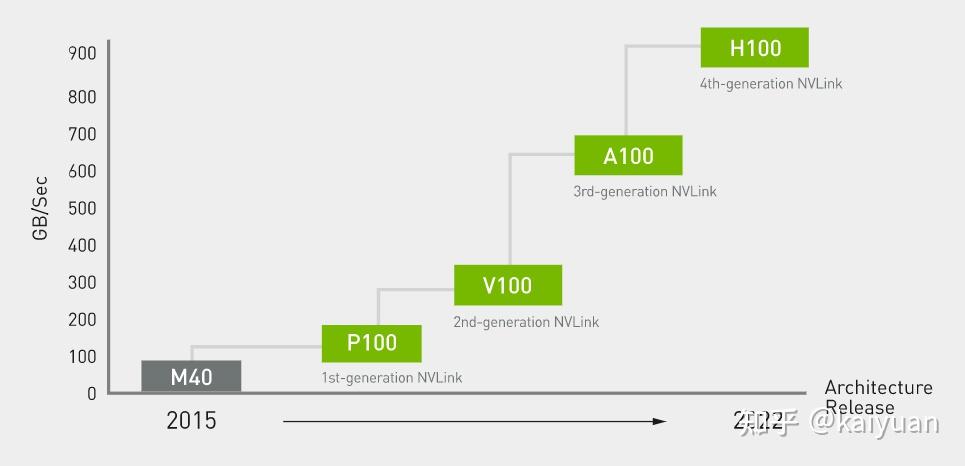
这里补充一下NVSwitch的作用。NVSwitch可以理解为卡与卡的集线器,能够提升卡与卡间的交互带宽,上面我们提到了NVLink有多个通道,但是这些通道并不是说都用来做两卡之间的连接, 这些通道需要搭建具体的topo结构,当机器中超过2张卡时,同一时刻卡与卡之间的带宽就不可能达到NVLink全部带宽。

NVSwitch的作用是让单GPU的NVLink带宽能力全部释放出来,比如服务器节点上面有8张GPU,那么同一时刻就能实现4对GPU-GPU的通信,大家带宽都是600GB/sec。
NVLink 是一种 GPU 之间的直接互连,可扩展服务器内的多 GPU 输入/输出 (IO)。NVSwitch 可连接多个 。NVLink,在单节点内和节点间实现以 NVLink 能够达到的最高速度进行多对多 GPU 通信。

查看机器中NVLink 的topo结构:
# nvidia-smi topo -m
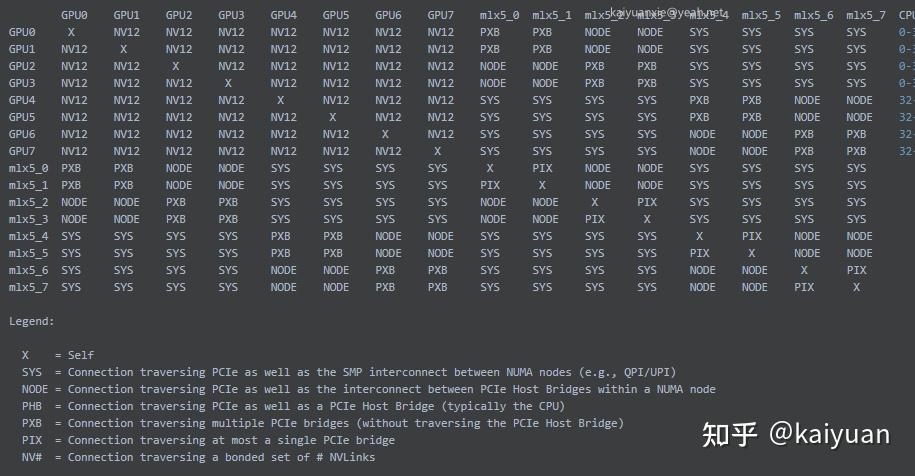
注:mlx5 是IB连接。
3 实践测试
为了进一步的了解Apmere架构,通过实际测试A100来了解其性能,实践中采用的两台配备了8张显卡的设备。由于设备成本昂贵,机器租用的是XX云的服务器。
设备1-A100机器主要参数:
> 显卡:NVIDIA A100-SXM4-80GB * 8
> 内存:1T
> CPU:Intel(R) Xeon(R) Platinum 8378A CPU @ 3.00GHz * 128
设备2-V100机器主要参数:
> 显卡:Tesla V100-SXM2-32GB * 8
> 内存:502G
> CPU: Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz * 72注:A100有两个规格,A100-80G比A100-40G的性能更好;SXM是GPU与主机连接的一种方式,与PCIe相对,SXM 显存带宽大于PCIe。
3.1 基本功能
3.1.1 矩阵操作测试
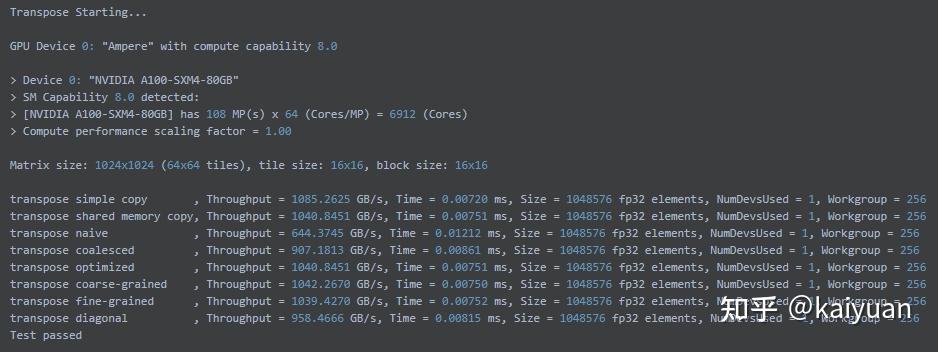
本测试中使用的是NVIDIA提供的测试标准矩阵:Matrix size: 1024x1024 (64x64 tiles), tile size: 16x16, block size: 16x16。对矩阵进行一些基本的操作,如拷贝、对角运算等,通过获得计算的时间来得到GPU的处理速度。
A100结果:
V100结果:
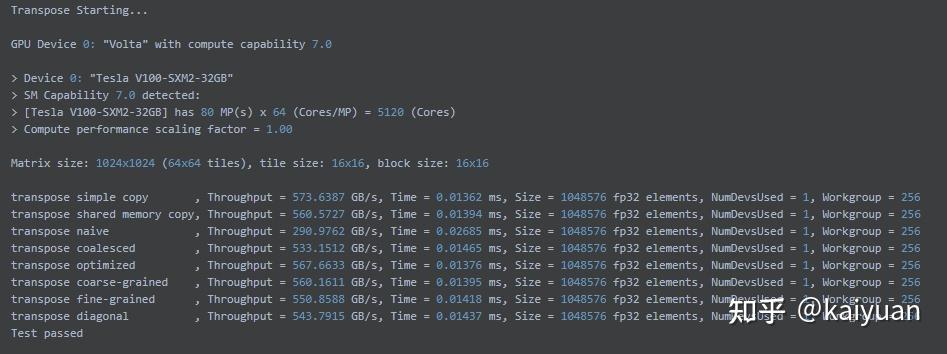
可以看到A100卡与V100相比,在处理速度上基本上是翻一倍的水平。
3.1.2 带宽测试
带宽测试主要是计算GPU与主机、GPU内部的数据传输速度,我们用cudaMemcpy可以测试数据传输的带宽,拷贝的形式有三种:
- cudaMemcpyHostToDevice: 主机到GPU;
- cudaMemcpyDeviceToHost: 设备到主机;
- cudaMemcpyDeviceToDevice:GPU到GPU(GPU内部数据传输);
三种方式使用的代码类似,区别主要是指针类型和cudaMemcpy的参数,如下例出GPU2GPU数据转移的代码:
///////////////////////////////////////////////////////////////////////////////
// GPU-> GPU数据传输
///////////////////////////////////////////////////////////////////////////////
float testDeviceToDeviceTransfer(unsigned int memSize) {
StopWatchInterface *timer = NULL;
float elapsedTimeInMs = 0.0f;
float bandwidthInGBs = 0.0f;
cudaEvent_t start, stop;
sdkCreateTimer(&timer);
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
unsigned char *h_idata = (unsigned char *)malloc(memSize);
if (h_idata == 0) {
fprintf(stderr, "Not enough memory avaialable on host to run test!\n");
exit(EXIT_FAILURE);
}
for (unsigned int i = 0; i < memSize / sizeof(unsigned char); i++) {
h_idata = (unsigned char)(i & 0xff);
}
unsigned char *d_idata;
checkCudaErrors(cudaMalloc((void **)&d_idata, memSize));
unsigned char *d_odata;
checkCudaErrors(cudaMalloc((void **)&d_odata, memSize));
checkCudaErrors(
cudaMemcpy(d_idata, h_idata, memSize, cudaMemcpyHostToDevice));
sdkStartTimer(&timer);
checkCudaErrors(cudaEventRecord(start, 0));
for (unsigned int i = 0; i < MEMCOPY_ITERATIONS; i++) {
checkCudaErrors(
cudaMemcpy(d_odata, d_idata, memSize, cudaMemcpyDeviceToDevice));
}
checkCudaErrors(cudaEventRecord(stop, 0));
checkCudaErrors(cudaDeviceSynchronize());
sdkStopTimer(&timer);
checkCudaErrors(cudaEventElapsedTime(&elapsedTimeInMs, start, stop));
if (bDontUseGPUTiming) {
elapsedTimeInMs = sdkGetTimerValue(&timer);
}
double time_s = elapsedTimeInMs / 1e3;
// GPU->GPU 设备内带宽计算前面乘以了2。GPU <-> Host 不需要乘以2:
bandwidthInGBs = (2.0f * memSize * (float)MEMCOPY_ITERATIONS) / (double)1e9;
bandwidthInGBs = bandwidthInGBs / time_s;
sdkDeleteTimer(&timer);
free(h_idata);
checkCudaErrors(cudaEventDestroy(stop));
checkCudaErrors(cudaEventDestroy(start));
checkCudaErrors(cudaFree(d_idata));
checkCudaErrors(cudaFree(d_odata));
return bandwidthInGBs;
}
A100结果:
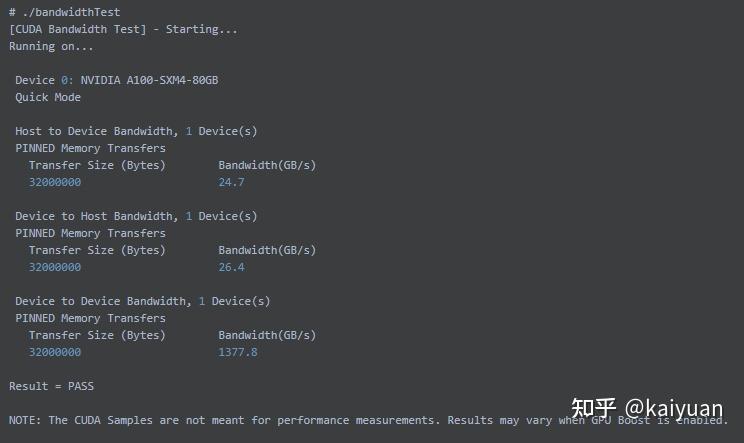
V100结果:
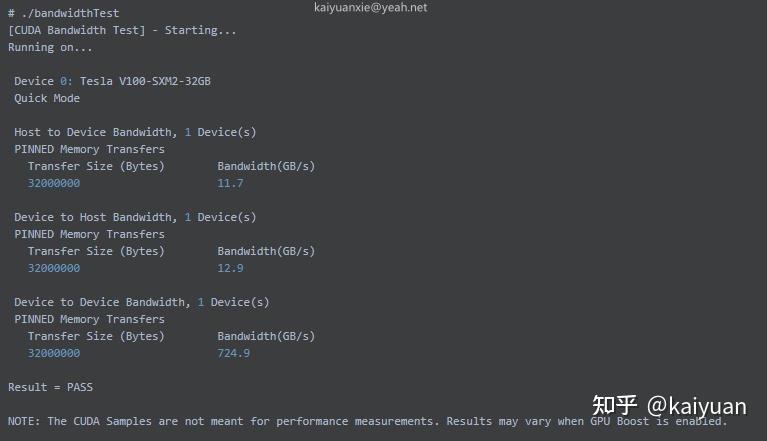
对比结果可知,A100的PCIe速度比V100快了1倍还多,内部GPU2GPU的带宽A100(相比V100)近乎翻倍。A100支持的是第四代PCIe理论上是31.5GB/s 的带宽,这里测到了25GB/s的带宽,相差的大小只有5GB/s左右,算是一个不错的表现。
3.1.3 NVLink测试
NVLink的测试需要使用P2P功能,一般采用cudaMemcpyPeer来完成数据Copy操作。
// 关键代码如下:
cudaSetDevice(0);
unsigned char *d_idata;
checkCudaErrors(cudaDeviceEnablePeerAccess(1, 0)); // 需要写在cudaSetDevice设置后,表示打开与1号卡的P2P通信
checkCudaErrors(cudaMalloc((void **)&d_idata, memSize));
cudaSetDevice(1);
unsigned char *d_odata;
checkCudaErrors(cudaDeviceEnablePeerAccess(0, 0)); // 1号卡,打开与0号卡的P2P通信。 参数2:必须填0。
checkCudaErrors(cudaMalloc((void **)&d_odata, memSize));
cudaSetDevice(0);
checkCudaErrors(
cudaMemcpy(d_idata, h_idata, memSize, cudaMemcpyHostToDevice));
sdkStartTimer(&timer);
checkCudaErrors(cudaEventRecord(start, 0));
for (unsigned int i = 0; i < MEMCOPY_ITERATIONS; i++) {
checkCudaErrors(
cudaMemcpyPeer(d_odata, 1, d_idata, 0, memSize));
}
A100数据传输速度:
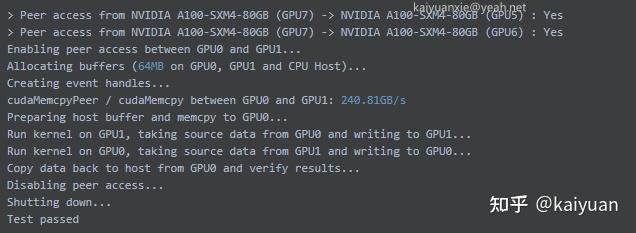
V100数据传输速度:
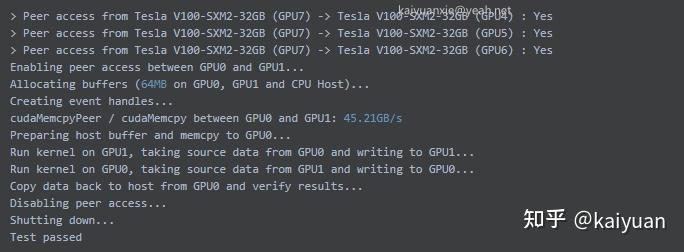
从结果可知,NVLink传输速度的测试并没有达到NVIDIA官方的宣传效果。A100(第三代NVLink)理论的速度是600GB/s,这里测到是240.81GB/s;V100使用的是第二代NVLink,理论速度是300GB/s ,这里测到的只有45.21GB/s。 总体来说,A100的NVLink速度还是比PCIe快了非常多,上升了一个量级。
3.1.4 NVJPG解码测试
由于A100增加了JPG硬件,有助于Jpeg图片解码速度的提升,这里用开源的Imagenet/train图片对该硬件进行测试。测试图片在机器的固态硬盘中,用CUDA里面nvjpegDecode 函数来解码图片。关键代码如下:batch_size=32。
checkCudaErrors(cudaEventRecord(startEvent, params.stream));
for (int i = 0; i < batch_size; i++) {
checkCudaErrors(nvjpegDecode(params.nvjpeg_handle, params.nvjpeg_state,
(const unsigned char *)img_data.data(),
img_len, params.fmt, &out,
params.stream));
}
checkCudaErrors(cudaEventRecord(stopEvent, params.stream));
A100:
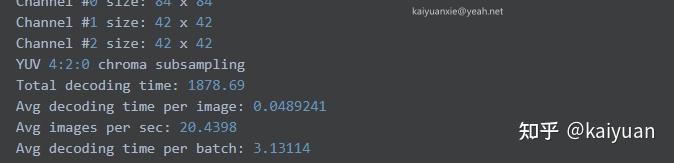
V100:
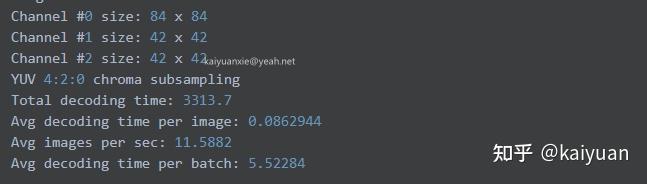
从数据可知,相比V100,A100对Jpeg图片的解码计算速度提升了0.9倍左右。
3.1.5 Reduce求和运算
A100上面推出了warp内的reduce操作(单步完成)函数,这些函数能够加速warp单元内的数据处理速度。比如求和运算,以前需要多次操作完成:在设备函数内用一个循环(for (int i=16; i>=1; i/=2))实现warpAdd,循环一共需要执行五次;或者直接执行五次,如下图中左所示,而A100上单步即可完成add操作(__reduce_add_sync),如下图右所示。
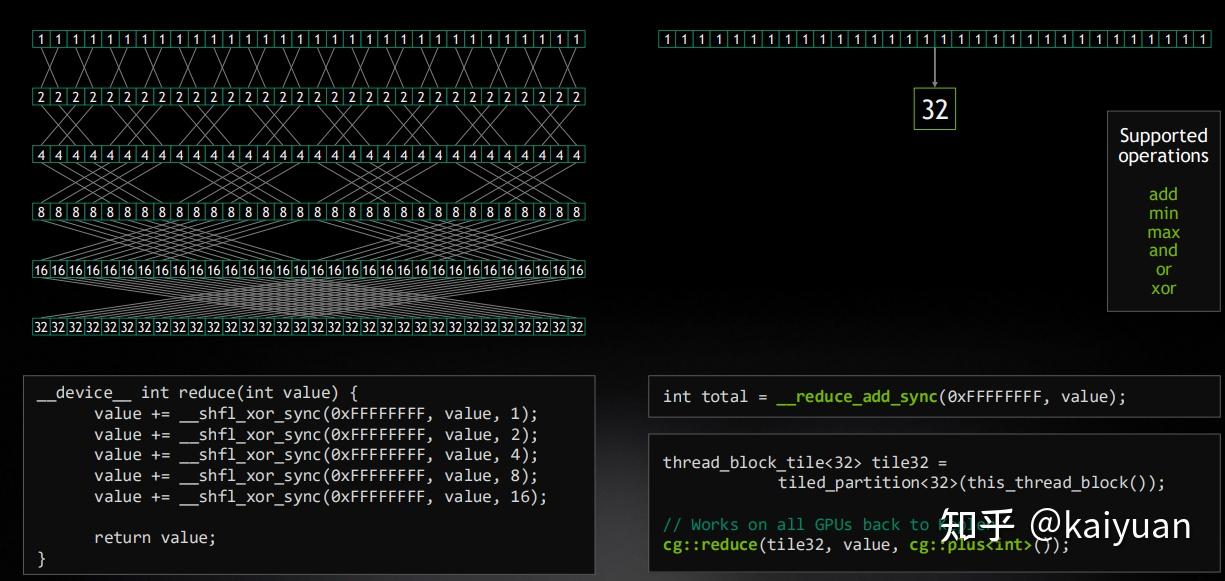
为了验证__reduce_add_sync 带来的速度提升,采用如下代码来测试运算速度:
// code author: 知乎 @ kaiyuan
// 编译 nvcc -lcuda reduce.cu -o reduce
#include <stdio.h>
#include <cuda_runtime.h>
#include <cooperative_groups.h>
#include <cooperative_groups/reduce.h>
namespace cg = cooperative_groups;
#define _CONVERT(x) #x
#define CONVERT(x) _CONVERT(x)
#define TIME_ELAPSE(func, elapsedTime, start, stop) \
cudaEventCreate(&start); \
cudaEventCreate(&stop); \
cudaEventRecord(start, 0); \
(func); \
cudaEventRecord(stop, 0); \
cudaEventSynchronize(stop); \
cudaEventElapsedTime(&elapsedTime, start, stop); \
printf(&#34;Func: %s, elapsedTime: %3.1f ms\n&#34;, CONVERT(func),elapsedTime); \
cudaEventDestroy(start); \
cudaEventDestroy(stop);
__global__ void shflWarpReduce() {
int laneId = threadIdx.x & 0x1f;
// Seed starting value as inverse lane ID
int value = 31 - laneId;
// Use XOR mode to perform butterfly reduction
for (int i=16; i>=1; i/=2)
value += __shfl_xor_sync(0xffffffff, value, i, 32);
}
__global__ void syncWarpReduce() {
auto block = cg::this_thread_block();
auto tile = cg::tiled_partition<32>(block);
int laneId = threadIdx.x & 0x1f;
// Seed starting value as inverse lane ID
int value = 31 - laneId;
//value = __reduce_add_sync(0xffffffff, value);
value = cg::reduce(tile, value, cg::plus<int>());
// &#34;value&#34; now contains the sum across all threads
// printf(&#34;Thread %d final value = %d\n&#34;, threadIdx.x, value);
}
void repeatRun(int times, void (*func)()) {
for (int i= 0; i < times; i++) {
func<<<1, 32>>>();
}
}
int main() {
float elapsedTime;
cudaEvent_t start, stop;
TIME_ELAPSE((repeatRun(1000, shflWarpReduce)), elapsedTime, start, stop);
TIME_ELAPSE((repeatRun(1000, syncWarpReduce)), elapsedTime, start, stop);
cudaDeviceSynchronize();
return 0;
}
在A100机器上面运行结果如下所示。经过反复测试获得的运行时间基本一致,测试未达到预期。测试中reduce操作并没有发挥应有的速度优势,可能是由于计算太过简单,时间都消耗在了数据的创建与传输上面,真正的计算并未消耗太多时间。(有更好的测试方法,欢迎留言)。

3.2 神经网络测试
从产品手册中可知,A100卡针对DL(深度学习)做了优化,特别是Tensor Core对深度学习有针对性优化。官方宣传的性能如下,里面包含了PyTorch bert模型测试。
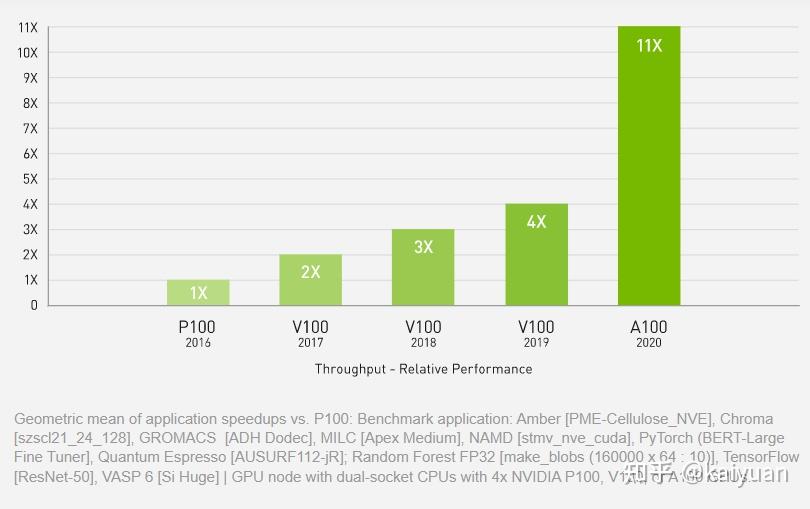
为了解A100在深度学习训练端到端的表现情况,这里使用pytorch框架和开源代码进行测试,模型:Resnext和Swin-transformer。
3.2.1 Resnext端测
Resnext 选用的模型来自torchvision:torchvision.models.resnext101_32x8d,为了提升模型对算力的使用量,数据使用了假数据(FakeData),单卡训练,测试代码如下:
# code author: 知乎 @ kaiyuan
import torch
import time
import torchvision
from torchvision import transforms
def main():
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.FakeData(size=1000, image_size=(3, 28, 28), num_classes=10, transform=trans)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set,
batch_size=1024,
num_workers=0,
pin_memory=True)
net = torchvision.models.resnext101_32x8d(num_classes=10)
net.conv1 = torch.nn.Conv2d(3, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
data = next(iter(data_loader_train))
images, labels = data
images = torch.tensor(images).cuda()
labels = torch.tensor(labels).cuda()
for epoch in range(10):
# for i, data in enumerate(data_loader_train):
for i in range(100):
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print(&#34;loss: {}&#34;.format(loss.item()))
if __name__ == &#34;__main__&#34;:
t1 = time.time()
main()
t2 = time.time()
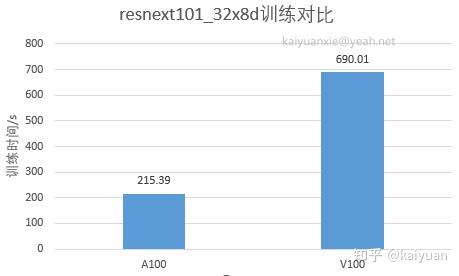
print(&#34;t2 - t1:{}&#34;.format(t2 - t1))结果如下所示,可以看到A100机器的运算时间只有V100的三分之一不到,也就是说该场景下,A100速度是V100的3倍。
3.2.2 Swin-transformer端测
Transformer是当下比较流行的网络架构,英伟达在Hopper架构上面甚至针对它进行了硬件优化,这里我们选用swin-transformer训练来测试A100的性能,对比的GPU还是用V100。本测试的代码来源:CODE,数据采用的是Imagenet的部分数据,大小691MB。
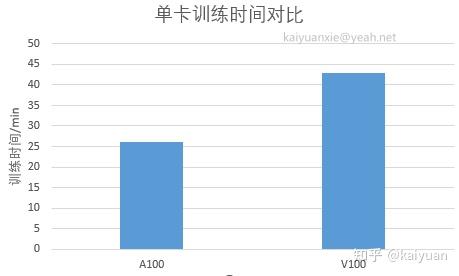
场景1: 单卡训练测试
训练的epoch数量为10,启动参数配置:
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --nproc_per_node 1 --master_port 22345 main.py --cfg configs/swin/swin_base_patch4_window7_224.yaml --data-path ../Imagenet-mini --batch-size 128A100结果:

V100结果:

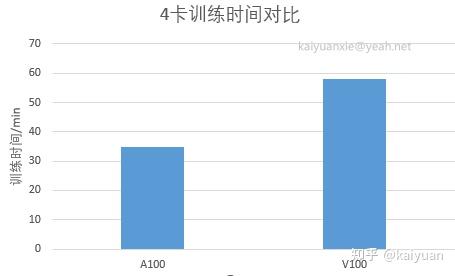
场景2:四卡训练测试
训练的epoch数量为50,启动参数配置:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node 4 --master_port 22345 main.py --cfg configs/swin/swin_base_patch4_window7_224.yaml --data-path ../Imagenet-mini --batch-size 128A100结果:
[swin_base_patch4_window7_224](main.py 277): INFO * Acc@1 1.177 Acc@5 7.208y
[swin_base_patch4_window7_224](main.py 159): INFO Accuracy of the network on the 9600 test images: 1.2%
[swin_base_patch4_window7_224](main.py 161): INFO Max accuracy: 4.65%
[swin_base_patch4_window7_224](main.py 165): INFO Training time 0:35:14V100结果:
[swin_base_patch4_window7_224](main.py 277): INFO * Acc@1 1.250 Acc@5 7.240
[swin_base_patch4_window7_224](main.py 159): INFO Accuracy of the network on the 9600 test images: 1.3%
[swin_base_patch4_window7_224](main.py 161): INFO Max accuracy: 4.65%
[swin_base_patch4_window7_224](main.py 165): INFO Training time 0:58:21对比:
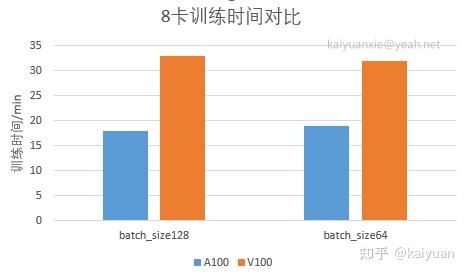
场景3:八卡训练测试
训练的epoch数量为50,启动参数配置:
python -m torch.distributed.launch --nproc_per_node 8 --master_port 22345 main.py --cfg configs/swin/swin_base_patch4_window7_224.yaml --data-path ../Imagenet-mini --batch-size 128A100结果:

V100结果:

场景4:八卡训练测试(小batch_size)
训练的epoch数量为50,batch_size为64,启动参数配置:
python -m torch.distributed.launch --nproc_per_node 8 --master_port 22345 main.py --cfg configs/swin/swin_base_patch4_window7_224.yaml --data-path ../Imagenet-mini --batch-size 64A100结果:
[swin_base_patch4_window7_224](main.py 277): INFO * Acc@1 1.240 Acc@5 7.094
[swin_base_patch4_window7_224](main.py 159): INFO Accuracy of the network on the 9600 test images: 1.2%
[swin_base_patch4_window7_224](main.py 161): INFO Max accuracy: 4.70%
[swin_base_patch4_window7_224](main.py 165): INFO Training time 0:19:48V100结果:
[swin_base_patch4_window7_224](main.py 277): INFO * Acc@1 1.260 Acc@5 7.177
[swin_base_patch4_window7_224](main.py 159): INFO Accuracy of the network on the 9600 test images: 1.3%
[swin_base_patch4_window7_224](main.py 161): INFO Max accuracy: 4.72%
[swin_base_patch4_window7_224](main.py 165): INFO Training time 0:32:52对比:
通过单测和端测的表现来看,A100的各项性能相比上一代数据中心产品V100确实提升了不少,其中差距最为明显的是P2P的实测带宽;除了速度以外大显存也是A100的一个优势,比如Transformer测试中80G的内存能够将batch_size上调到1024,而V10032G最多能设置到128 (2的指数倍),到256就会OOM。当然,本文并没有实际去测一些细微的单项指标,比如FP64的吞吐测试,如果对这些数据指标对比感兴趣可以留言。
参考资料:
- 【Ampere架构 GA100白皮书】
- 【Ampere架构 GA102白皮书】
- 【A100特性手册】:“NVIDIA A100 TENSOR CORE GPU”;
- 【A100 80G pcie产品】:A100 80GB 的产品介绍;
- 【A100 40GB规格pcie产品手册】:产品介绍;
- NVIDIA Tensor Cores: Versatility for HPC & AI
- 【OLCF_Users_Call_Oct2020】
注:<2022.9.1:A100 被A国禁售了(对英伟达的限制影响),禁令2023年X月生效。目前来看影响不大,国内大厂还有存量,还能继续使用>
文中的不足之处欢迎指正,需要可以点赞、收藏。 |
|



 发表于 2022-9-21 15:59:48
发表于 2022-9-21 15:59:48

